Ch 1 爬虫基础
HTTP基本原理
URI和URL
URI的全称为 Uniform Resource Identifier,即统一资源标志符。
URL的全称为 Universal Resource Locator,即统一资源定位符。
URN的全称为 Universal Resource Name,即统一资源名称。
三者关系为: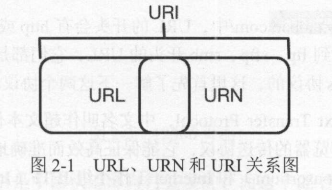
超文本
HypeText
HTTP和HTTPS
HTTP的全称是Hyper Text Transfer Protocol,超文本传输协议。
HTTPS的全称是Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的HTTP通道,简单讲是 HTTP 的安全版,即HTTP下加入 SSL层,简称为HTTPS。
HTTP请求过程
请求
请求方法

请求网址
URL请求头
用来说明服务器要使用的附加信息。
因此,请求头是请求的重要组成部分,在写爬虫时,大部分情况下都需要设定请求头。
请求体
一般承载的内容是POST请求中的表单数据,而对于GET请求,请求体则为空。
在爬虫中,如果要构造POST请求,需要使用正确的Content-Type,并了解各种请求库的各个参数设置时使用的是哪种Content-Type, 不然可能会导致POST提交后无法正常响应。
响应
响应状态码
响应状态码表示服务器的响应状态。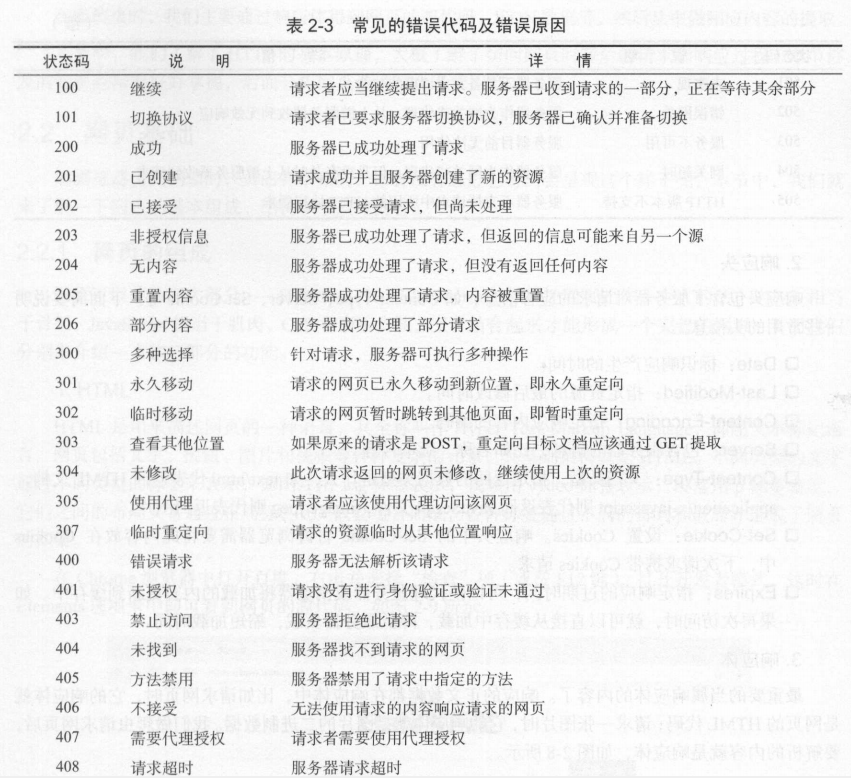

响应头
响应头包含了服务器对请求的应答信息。
响应体
响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码;请求一张图片时,它的响应体就是图片的二进制数据。
网页基础
网页的组成
网页可以分为三大部分——HTML,CSS和JavaScript。如果把网页比作一个人的话, HTML相于骨架,JavaScript相当于肌肉,CSS相当于皮肤。
- HTML
HTML是用来描述网页的一种语言,其全称叫作Hyper Text Markup Language,即超文本标记语言。 - CSS
CSS,全称叫作Cascading Style Sheets,即层叠样式表。 - JavaScript
JavaScript,简称JS,是一种脚本语言,实现了一种实时、动态、交互的页面功能。
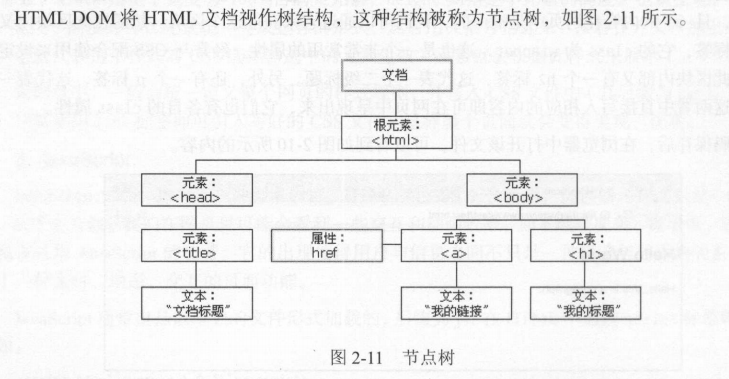
网页的结构
|
节点树及节点间关系

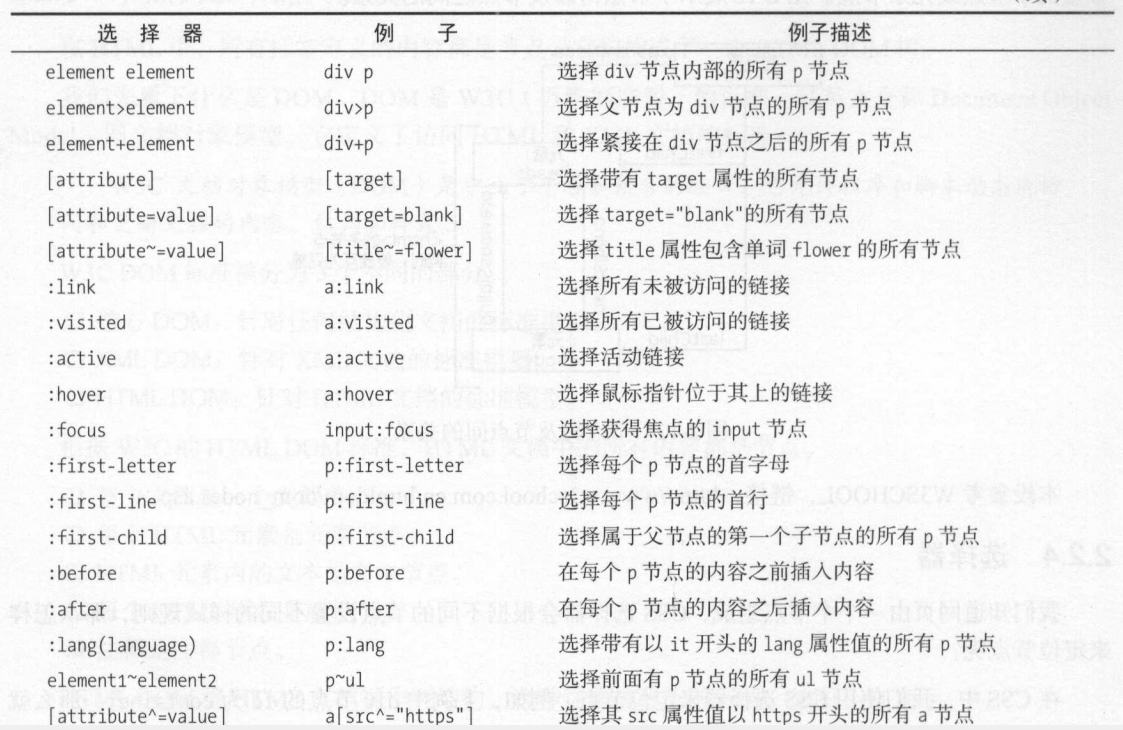
选择器
常用三种方法:根据id(#)、根据class(.)以及标签名(h1)进行筛选。
嵌套选择:
- 各选择器之间加空格代表嵌套关系,如div #container为先选择一个div节点,在选择其内部id为container的节点。
- 不加空格代表并列关系,如div#container为选择id为container的div节点。
css选择器还有一些其他语法规则,具体如表2-4所示。

爬虫的基本原理
爬虫概述
- 获取网页
- 提取信息
- 保存数据
- 自动化程序
能抓怎样的数据
HTML代码、JSON文件、二进制数据等
JavaScript渲染页面
通过分析其后台Ajax接口,或使用Selenium、Splash库来模拟JavaScript渲染。
会话和Cookies
静态网页和动态网页
无状态HTTP
HTTP连接本身是无状态的。
会话
Web中,会话对象用来存储特定用户会话所需的属性及配置信息。Cookies
Cookies指某些网站为了辨别用户身份、进行会话跟踪而存储在用户本地终端上的数据。会话维持
当客户端第一次请求服务器时,服务器会返回一个请求头中带有Set-Cookie字段的响应给客户端,用来标记是哪一个用户,客户端浏览器会把Cookie保 存起来。当浏览器下一次再请求该网站时,浏览器会把此Cookies放到请求头一起提交给服务器,“Cookies携带了会话ID信息,服务器检查该Cookies即可找到对应的会话是什么,然后再判断会话来以此来辨认用户状态。属性结构
- Name:该Cookie的名称。一旦创建,该名称便不可更改。
- Value:该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。
- Domain:可以访问该 Cookie 的域名 。 例如,如果设置为 . zhihu.com ,则所有以 zh ihu .com 结尾的域名都可以访问该 Cookie。
- Max Age:该Cookie失效的时间,单位为秒,也常和Expires一起使用,通过它可以计算出其有效时间。Max Age如果为正数,则该Cookie在Max Age 秒之后失效。如果为负数,则关闭浏览器时Cookie即失效,浏览器也不会以任何形式保存该Cookie。
- Path:该Cookie的使用路径。如果设置为/path/,则只有路径为/path/的页面可以访问该Cookie;如果设置为/,则本域名下的所有页面都可以访问该Cookie。
- Size字段:此Cookie的大小。
- HTTP字段:Cookie的httponly属性。若此属性为true,则只有在HTTP头中会带有此Cookie的信息,而不能通过document.cookie来访问此Cookie。
- Secure:该Cookie是否仅被使用安全协议传输。安全协议有HTTPS和SSL等,在网络上传输数据之前先将数据加密。默认为false。
会话Cookie和持久Cookie
表面意思为会话Cookie存在浏览器内存里,浏览器关闭则Cookie失效;持久Cookie保存在硬盘里,下次可再次使用。
实际为设置Cookie的Max Age或Expires字段。
常见误区
“浏览器关闭,会话就消失了”。是不准确的。
代理的基本原理
基本原理
本机的网络请求通过代理服务器访问Web服务器。
代理的作用
- 突破自身IP访问限制。
- 访问一些单位或团体内部资源。
- 提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将·其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度。
- 隐藏真实IP:免受攻击或防止IP被封锁。
代理分类
- 根据协议区分
- FTP代理服务器:主要用于访问FTP服务器,一般有上传、下载以及缓存功能,端口一般为21、2121等。
- HTTP代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口一般为80、8080、3128等。
- SSl/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持128位加密强度),端口一般为443。
- RTSP代理:主要用于访问Real流媒体服务器,一般有缓存功能,端口一般为554。
- Telnet代理:主要用于telnet远程控制(黑客人侵计算机时常用于隐藏身份),端口一般为23。
- POP3/SMTP代理:主要用于POP3/SMTP方式收发邮件,一般有缓存功能,端口一般为110/25。
- SOCKS代理:只是单纯传递数据包,不关心具体协议和用法,所以速度快很多,一般有缓存功能,端口一般为1080。SOCKS代理协议又分为SOCKS4和SOCKS5,前者只支持TCP,而后者支持TCP和UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说,SOCKS4能做到的SOCKS5都可以做到,但 SOCKS5能做到的SOCKS4不一定能做到。
- 根据匿名程度区分
- 高度匿名代理:会将数据包原封不动地转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的IP是代理服务器的IP。
- 普通匿名代理:会在数据包上做一些改动,服务端上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实IP。代理服务器通常会加入的HTTP头有HTTP_VIA和 HTTP_X_FORWARDED_FOR。
- 透明代理:不但改动了数据包 还会告诉服务器客户端的真实IP。这种代理除了能用缓存技术提高浏览速度,能用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网巾的硬件防火墙。
- 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
常见代理设置
- 网上的免费代理
- 付费代理服务
- ADSL拨号:拨一次号换一次IP,稳定性高。
Ch 2 基本库的使用
使用urllib
urllib为Python内置的HTTP请求库,包含以下4个模块:
- request:它是最基本的HTTP请求模块,可以用来模拟发送请求。
- error:异常处理模块。
- parse:一个工具模块,提供了许多URL处理方法,比如拆分、解析、合并等。
- robot parser:主要是用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬,用得比较少。
发送请求
- urlopen()
urlopen()返回一个HTTPResponse类型的对象,主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等属性。
urlopen()函数的API:示例:urllib.request.urlopen(url, data=None, timeout=1, cafile=None,
capath=None, cadefault=False, context=None)
data:需要是字节流编码格式,即bytes类型,请求方法变为POST
timeout:单位为秒
cafile和capath:指定CA证书及其路径
cadefault:已弃用
context:用来指定SSL设置,必须是ssl.SSLContext类型import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word':'hello'}), encoding='utf-8')
response= urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read()) - Request类
API:示例:class urllib.request.Request(ur1, data=None, headers={},
origin_req_host=None, unverifiable=False, method=None)
headers:为一个字典,用来构造请求头,也可以后面用add_header()添加,常用来修改User-Agent
origin_req_host:请求方的host名称或IP地址
unverifiable:请求权限问题
method:请求方法from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (Compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8')) - 用Opener构建Handler
官方文档:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler- 验证
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'http://localhost:5000/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason) - 代理
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason) - Cookies
- 获取Cookies
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value) - Cookie保存至文件
import http.cookiejar
import urllib.request
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
#cookie = http.cookiejar.LWPCookieJar(filename) 另一种格式
#cookie.load('cookies.txt', ignore_discard=True, ignore_expires=True) 读取
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
- 获取Cookies
- 验证
处理异常
- URLError
from urllib import request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason) - HTTPError
URLError是HTTPError的父类,所以可以先选择捕获子类的错误,再去捕获父类的错误。from urllib import request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
解析链接
url.parse模块,定义了处理URL的标准接口,例如实现URL各部分的抽取、合并以及链接转换。
支持如下协议的URL处理:file、ftp、gopher、hdl、http、https、imap、mailto、mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、sip、sips、snews、svn、svn+ssh、telnet和wais。
常用方法如下:
urlparse()
实现URL的识别与分段。
API:urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
scheme:url中没有协议时,作为默认的协议。
allow_fragments:是否忽略fragment。如果设置为False,fragment部分就会被忽略,
它会被依次解析为query、parameters或者path的一部分,而fragment部分为空。示例:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment',
scheme='https', allow_fragments=False)
print(result) #返回的result为ParseResult类型,实际上是一个元组,支持result[0]和result.scheme
Output:
ParseResult(scheme='http', netloc='www.baidu.com',
path='/index.html#comment', params='', query='', fragment='')urlunparse()
实现URL的构造。from urllib.parse import urlunparse
#data可以用其他类型,但长度必须是6
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
Output:
http://www.baidu.com/index.html;user?a=6#commenturlsplit()
类似urlparse(),但只返回5个结果,params合并到path里。from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result)
Output:
SplitResult(scheme='http', netloc='www.baidu.com',
path='/index.html;user', query='id=5', fragment='comment')urlunsplit()
类似urlunparse(),但只传入5个参数。urljoin()
from urllib.parse import urljoin
urljoin(base_url, target_url)
分析base_url的scheme、netloc和path三个内容并对target_url进行补充urlencode()
将字典序列化为GET请求的参数。from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)
Output:
http://www.baidu.com?name=germey&age=22parse_qs()
将URL反序列化为字典。from urllib.parse import parse_qs
query = 'name=germey&age=22'
print(parse_qs(query))
Output:
{'name': ['germey'], 'age': ['22']}parse_qsl()
将URL转化为元组组成的列表。[('name', 'germey'), ('age', '22')]
quote()
将内容(中文字符)转化为URL编码的格式。from urllib.parse import quote
keyword = '壁纸'
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)
Output:
https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8unquote()
进行URL解码
分析Robots协议
Robots协议
Robots协议也称作爬虫协议、机器人协议,全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作robot.txt的文本文件,一般放在网站的根目录下。爬虫名称
常见的搜索爬虫的名称及对应的网站:
BaiduSpider 百度 www.baidu.com
Googlebot 谷歌 www.google.com
360Spider 360 搜索 www.so.com
YodaoBot 有道 www.youdao.com
ia_archiver Alexa www.alexa.cn
Scooter altavista www.altavista.comrobotparser
urllib.robotparser模块提供了一个RobotFileParser类,该类的一些方法如下:- set_url():用来设置robots.txt文件的链接。也可在创建RobotFileParser对象时传入链接。
- read():读取robots.txt文件并进行分析。
- parse():用来解析robots.txt文件,传人的参数是robots.txt某些行的内容,它会按照robots.txt的语法规则来分析这些内容。
- can_fetch():该方法传人两个参数,第一个是 User-agent,第二个是要抓取的URL。返回的内容是该搜索引擎是否可以抓取这个URL,结果为True 或False。
- mtime():返回的是上次抓取和分析robots.txt的时间,这对于长时间分析和抓取的搜索爬虫是有必要的,可能需要定期检查来抓取最新的robots.txt。
- modified():同样对长时间分析和抓取的搜索爬虫很有帮助,将当前时间设置为上次抓取和分析robots.txt的时间。
示例:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('http://www.jianshu.com/robots.txt')
rp.read()
#上面两行可以用parse方法来执行读取和分析
#rp.parse(urlopen('http://www.jianshu.com/robots.txt').read().decode('utf-8').split('\n'))
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*', "http://www.jianshu.com/search?q=python&page=1&type=collections"))
Output:
True
False
使用requests
解决urllib中Cookies、登录验证、代理设置不方便的问题。
安装pip install requests
requests的官方文档:http://docs.python-requests.org/
基本用法
requests库包含get()、post()、put()、delete()、head()和options()等方法,分别对应各种方式请求网页。
GET请求
- 基本实例:
import requests
data = {
'name': 'germey',
'age': 22
}
r = requests.get("http://httpbin.org/get", params=data)
print(type(r))
print(r.status)
#网页的返回类型实际是JSON格式的str类型,调用json()可将其转化为字典
print(type(r.json()))
Output:
<class 'requests.models.Response'>
200
<class 'dict'> - 抓取网页
import requests
import re
headers = {
'User-Agent': ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36')
}
r = requests.get("https://www.zhihu.com/explore", headers=headers)
pattern = re.compile('explore-feed.*?question_link.*?>(.*?)</a>', re.S)
titles = re.findall(pattern, r.text)
print(titles) - 抓取二进制数据
import requests
r = requests.get("https://github.com/favicon.ico")
with open('favicon.ico', 'wb') as f:
f.write(r.content)
- 基本实例:
POST请求
import requests
data = {'name': 'germey', 'age': '22'}
r = requests.post("http://httpbin.org/post", data=data)响应
import requests
r = requests.get('http://www.xxyr.cc')
print(type(r.status_code))
print(type(r.headers))
print(type(r.cookies))
print(type(r.url))
print(type(r.history))
print(type(r.text)) #返回内容的字符串形式
print(type(r.content)) #返回内容的二进制形式
print(requests.codes.ok) #内置的返回码
Output:
<class 'int'>
<class 'requests.structures.CaseInsensitiveDict'>
<class 'requests.cookies.RequestsCookieJar'>
<class 'str'>
<class 'list'>
<class 'str'>
<class 'bytes'>
200
高级用法
文件上传
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
print(r.text)Cookies
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)可将Cookie字段添加到headers里实现登录:
import requests
headers = {
'Cookie': 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.text)或将其作为cookie参数添加到get()方法里:
import requests
cookies = 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0'
jar = requests.cookies.RequestsCookieJar()
headers = {
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('http://www.zhihu.com', cookies=jar, headers=headers)
print(r.text)会话维持
当访问登录网站后的页面,或同一站点的不同页面时,就需要进行会话维持。import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
Output:
{
"cookies": {
"number": "123456789"
}
}SSL证书验证
import requests
response = requests.get('https://www.12306.cn', verify=False) #默认为True,自动验证证书
print(response.status_code)verify=False会忽略证书的验证,但会报一个警告,解决方法如下:- 设置忽略警告
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code) - 捕获警告到日志
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code) - 指定一个本地证书用作客户端证书
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)
- 设置忽略警告
代理设置
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('https://www.taobao.com', proxies=proxies)若要使用HTTP Basic Auth,可以使用如下代理形式:
import requests
proxies = {
'https': 'http://user:password@10.10.1.10:3128/',
}
requests.get('https://www.taobao.com', proxies=proxies)requests还支持SOCKS代理:
安装:pip3 install 'requests[socks]'import requests
proxies = {
'http': 'socks5://user:password@host:port',
'https': 'socks5://user:password@host:port'
}
requests.get('https://www.taobao.com', proxies=proxies)超时设置
为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没有得到响应就报错。import requests
r = requests.get('https://www.taobao.com', timeout=1)
print(r.status_code)timeout=1表示超时时间为1秒,默认为None,即永远等待。
实际上,请求分为两个阶段,即连接(connect)和读取(read)。上面设置的timeout将用作连接和读取这二者的timeout总和。
如果要分别指定,就可以传入一个元组:r = requests.get('https://www.taobao.com', timeout=(5,11, 30))身份认证
import requests
#auth=('username', 'password')即auth=HTTPBasicAuth('username', 'password')
r = requests.get('http://localhost:5000', auth=('username', 'password'))
print(r.status_code)此外requests还提供了其他认证方式,如OAuth认证等。
Prepared Request
用于将请求表示为数据结构,其中各个参数通过一个Request对象来表示。from requests import Request, Session
url = 'http://httpbin.org/post'
data = {
'name': 'germey'
}
headers = {
'User-Agent': ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 ')
('(KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36')
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
#Session的prepare_request()方法将其转化为一个Prepared Request对象
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
正则表达式
详见: 正则表达式复习
抓取猫眼电影排行
详见https://github.com/Python3WebSpider/MaoYan
Ch 3 解析库的使用
使用XPath
lxml库安装:pip install lxml
如果想查询更多XPath的用法,可以查看:http://www.w3school.eom.cn/xpath/index.asp
如果想查询更多lxml库的用法,可以查看:http://lxml.de/
XPath概览
- XPath,全称XML Path Language,即XML路径语言,是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但同样适用于HTML文档的搜索。
- XPath于1999年ll月16日成为W3C标准,它被设计为供XSLT、XPointer以及其他XML解析软件使用,更多的文档可以访问其官方网站:https://www.w3.org/TR/xpath。
Xpath常用规则

实例引入
from lxml import etree |
节点选择
- 所有节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//*') #选择所有节点
#result = html.xpath('//li') #选择所有li节点
print(result)
print(result[0])
#返回形式是一个列表,每个元素是Element类型
Output:
[<Element li at 0x2257c34aa48>, <Element li at 0x2257c34aa88>]
<Element li at 0x2257c34aa48> - 子节点
/是直接节点,//是所有节点。
如选择li节点的所有直接a子节点,可以用//li/a,
选择ul节点下的所有a子节点,可以用//ul//a - 父节点
首先选中href属性为link4.html的a节点,然后再获取其父节点,然后再获取其class属性。from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/../@class')
#或者
result = html.xpath('//a[@href="link4.html"]/parent::*/@class') - 按序选择具体参考:http://www.w3school.com.cn/xpath/xpath_functions.asp
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[1]/a/text()') #序号从1开始
result = html.xpath('//li[last()]/a/text()') #选取最后一个
result = html.xpath('//li[position()<3]/a/text()')#选取第1、2个
result = html.xpath('//li[last()-2]/a/text()') #选取倒数第三个 - 节点轴选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[1]/ancestor::*') #选取第一个li节点的所有祖先节点
result = html.xpath('//li[1]/ancestor::div') #选取第一个li节点的祖先div节点
result = html.xpath('//li[1]/attribute::*') #获取第一个li节点的所有属性值
result = html.xpath('//li[1]/child::a') #child::直接子节点
result = html.xpath('//li[1]/descendant::span') #descendant::子孙节点
result = html.xpath('//li[1]/following::*[2]') #following::当前结点之后的所有节点
result = html.xpath('//li[1]/following-sibling::*') #following-sibling::
#当前结点之后的所有同级节点
文本获取
from lxml import etree |
属性操作
- 属性获取
获取所有li节点下所有a节点的href属性:from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a/@href') - 属性匹配
通过属性筛选节点:from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a[@href="link1.html"]') - 属性多值匹配
用contains()函数:from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li")]/a/text()') - 多属性匹配
用运算符and来连接:XPath中的运算符:from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
使用Beautiful Soup
安装:pip install beautifulsoup4
简介
Beautiful Soup是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据.
官方解释如下:
- Beautiful Soup提供一些简单的、Python式的函数来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。不需要考虑编码方式,除非文档没有指定一个编码方式,这时仅需说明一下原始编码方式就可以了。
- Beautiful Soup已成为和lxml、html6lib 一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
解析器
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器。(推荐lxml)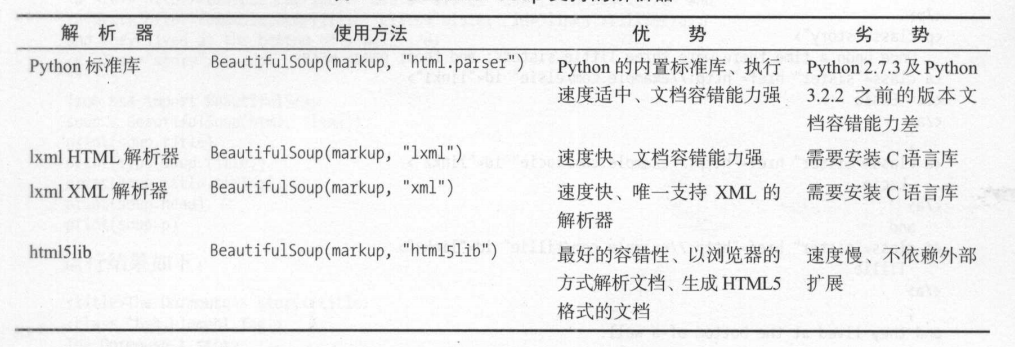
基本用法
from bs4 import BeautifulSoup |
节点选择器
- 选择元素
from bs4 import BeautifulSoup
html = ''
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p) #选择第一个匹配的p节点
Output:
<title>The Dormouse's story</title>
<class 'bs4.element.Tag'>
The Dormouse's story
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p> - 提取信息
- 获取名称
print(soup.title.name)
title - 获取属性或:
print(soup.p.attrs)
print(soup.p.attrs['name'])
{'class': ['title'], 'name': 'dromouse'}
dromouseprint(soup.p['class'])
print(soup.p['name'])
['title'] #class属性值可能有多个,所以返回列表
dromouse - 获取内容
print(soup.title.string) #选择第一个匹配的
The Dormouse's story
- 获取名称
- 嵌套选择
print(soup.head.title.string) #选择head内的title节点
The Dormouse's story - 关联选择
- 子节点和子孙节点
直接子节点:或soup.p.contents #返回包含各直接子节点的列表
子孙节点:for i, child in enumerate(soup.p.children): #返回生成器类型
print(i, child)for i, child in enumerate(soup.p.descendants):
print(i, child) - 父节点和祖先节点
直接父节点:祖先节点:print(soup.a.parent)
for i, parent in enumerate(soup.p.parents):
print(i, parent) - 兄弟节点
print('Next Sibling', soup.a.next_sibling)
print('Prev Sibling', soup.a.previous_sibling)
print('Next Siblings', list(enumerate(soup.a.next_siblings)))
print('Prev Siblings', list(enumerate(soup.a.previous_siblings))) - 提取信息
print(soup.a.next_sibling.string)
print(list(soup.a.parents)[0].attrs['class'])
- 子节点和子孙节点
方法选择器
- findall()
API:示例:find_all(name, attrs, recursive, text, **kwargs)
from bs4 import BeautifulSoup
html = ''
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(name='ul'))
print(type(soup.find_all(name='ul')[0]))
#返回结果为列表类型,每个元素为bs4.element.Tag类型
print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))
或
print(soup.find_all(id='list-1'))
print(soup.find_all(class_='element')) #class_因为是关键字
print(soup.find_all(text=re.compile('link')))
#参数可以是字符串,也可以是正则表达式对象 - find()
返回第一个匹配的元素。 - find_parents()和find_parent():前者返回所有祖先节点,后者返回直接父节点。
- find_next_siblings()和find_next_sibling():前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点。
- find_previous_siblings()和find_previous_sibling():前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点 。
- find_all_next()和find_next():前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点。
- find_all_previous()和find_previous():前者返回节点前所有符合条件的节点,后者返回第一个符合条件的节点。
CSS选择器
参考:http://www.w3school.com.cn/cssref/css_selectors.asp
from bs4 import BeautifulSoup |
使用pyquery
安装pip install pyquery
pyquery的官方文档:http://pyquery.readthedocs.io
初始化
import requests |
基本CSS选择器
关于CSS选择器的更多用法,可以参考:https://www.w3school.com.cn/css/css_selector_type.asp
from pyquery import PyQuery |
查找结点
下面介绍一些常用的查询函数,这些函数和jQuery中函数的用法完全相同。
from pyquery import PyQuery |
遍历
from pyquery import PyQuery |
获取信息
- 获取属性
提取到某个PyQuery类型的节点后,就可以调用attr()方法来获取属性:from pyquery import PyQuery
html = ''
doc = PyQuery(html)
a = doc('.item-0.active a')
print(a)
print(type(a))
print(a.attr('href')) #若a有多个,只返回第一个a的属性值
print(a.attr.href)
<a href="link3.html"><span class="bold">third item</span></a>
<class 'pyquery.pyquery.PyQuery'>
link3.html
link3.html - 获取文本
from pyquery import PyQuery
html = ''
doc = PyQuery(html)
li = doc('li')
print(li.html()) #返回第一个节点的内部HTML文本
print(type(li.html()))
print(li.text()) #返回所有节点内部的纯文本,中间用一个空格分隔开
print(type(li.text()))
<a href="link2.html">second item</a>
<class 'str'>
second item third item fourth item fifth item
<class 'str'>
节点操作
pyquery提供了一系列方法来对节点进行动态修改,比如为某个节点添加一个 class,移除某个节点等,如append()、empty()和prepend()等方法,它们和jQuery的用法完全一致,详细的用法可以参考官方文档:http://pyquery.readthedocs.io/en/latest/api.html
- addClass和removeClass
from pyquery import PyQuery
html = ''
doc = PyQuery(html)
li = doc('.item-0.active')
li.removeClass('active')
li.addClass('active') - attr、text和html
li.attr('name', 'link') #修改或增加name属性值为link
li.text('changed item') #将li节点内部的文本替换为纯文本
li.html('<span>changed item</span>')#将li节点内部的文本替换为HTML文本 - remove()
wrap = doc('.wrap')
wrap.find('p').remove()
type(wrap.find('p'))
<class 'pyquery.pyquery.PyQuery'>
伪类选择器
css选择器之所以强大,还有一个很重要的原因,就是支持多种多样的伪类选择器,例如选择第一个节点、最后一个节点、奇偶数节点、包含某一文本的节点等。示例如下:
from pyquery import PyQuery |
Ch 4 数据存储
文件存储
TXT文本存储
with open('test.txt', 'a', encoding='utf-8') as file: |
打开方式:
- r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
- rb:以二进制只读方式打开一个文件。文件指针将会放在文件的开头。
- r+:以读写方式打开一个文件。文件指针将会放在文件的开头。
- rb+:以二进制读写方式打开一个文件。文件指针将会放在文件的开头。
- w:以写入方式打开一个文件。如果该文件已存在,则将其瞿盖。如果该文件不存在,则创建新文件。
- wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
- ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件来写入。
- a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果眩文件不存在,则创建新文件来读写。
- ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件用于读写。
JSON文件存储
JSON,全称为JavaScript Object Notation,也就是JavaScript对象标记,通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。
对象和数组:
- 对象:在JavaScript中使用花括号{}包裹起来的内容,数据结构为{ keyl : valuel, key2 : value2, … }的键值对结构。 在面向对象的语言中,key为对象的属性,value为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
- 数组:数组在JavaScript中是方括号[]包裹起来的内容,数据结构为[ “java”, “javascript”]的索引结构。在JavaScript中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
示例:loads()和dumps()
import json |
若json文件包含多条记录,可以:
#逐行读取 |
参见:
json.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 190) [duplicate]
Python json.loads shows ValueError: Extra data
CSV文件存储
CSV,全称为Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。
- 写入
import csv
with open ('data.csv', 'w', encoding='utf-8') as csvfile:
#delimiter指定分隔符 lineterminator指定行终止符,默认\n
writer = csv.writer(csvfile, delimiter=' ', lineterminator='\n\n')
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', 20])
writer.writerow(['10002', 'Bob', 22])
#写入多行
writer.writerows(['10001', 'Mike', 20], ['10002', 'Bob', 22])
#字典写入
fieldnames = ['id', 'name', 'age')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer. writeheader()
writer.writerow({'id': '10001', 'name' :'Mike', 'age' : 20})
writer.writerow({'id': '10002', 'name' : 'Bob', 'age' : 22})
writer.writerow({'id': '10003', 'name' :'Jordan', 'age' : 21}) - 读取
import csv
with open('data.csv','r', encoding='utf 8') as csvfile:
reader = csv.reader(csvfile)
# fileData = list(reader) #fileData[0][0]
for row in reader:
print('row'+str(row.line_num)+str(row))
#或
import pandas as pd
df = pd.read csv('data.csv')
print(df)
关系型数据库存储
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。
表可以看作某个实体的集合,而实体之间存在联系,这就需要表与表之间的关联关系来体现,如主键外键的关联关系。多个表组成一个数据库,也就是关系型数据库。
MySQL存储
相关链接:
- GitHub: https://github.com/PyMySQL/PyMySQL
- 官方文档:http://pymysql.readthedocs.io/
- PyPI: https://pypi.python.org/pypi/PyMySQL
安装:pip install pymysql
相关操作:
- 连接、创建数据库
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456', port=3306)
cursor = db.cursor() #获得操作游标
cursor.execute('SELECT VERSION()')
data = cursor.fetchone() #获得第一条数据
print('Database version:', data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8")
db.close()
Output:
Database version: ('5.7.29-log',) - 创建表
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql)
db.close() - 插入数据改进,根据字典动态构造:
import pymysql
id = '20120001'
user = 'Bob'
age = 20
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id, name, age) values(%s, %s, %s)' #采用格式化符%而非字符串拼接
try:
cursor.execute(sql, (id, user, age))
db.commit()
except:
db.rollback()
db.close()这里涉及事务的问题,事务的特性如下:import pymysql
data = {
'id': '20120001',
'name': 'Bob',
'age': 20
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
#INSERT INTO students(id , name, age) VALUES (%s, %s, %s)
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
try:
if cursor.execute(sql, tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()- 原子性(atomicity):事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency):事务必须使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation):一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability):持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
- 更新数据改进,字典传值+去重:
sql = 'UPDATE students SET age = %s WHERE name = %s'
try:
cursor.execute(sql, (25, 'Bob'))
db.commit()
except:
db.rollback()import pymysql
data = {
'id': '20120001',
'name': 'Bob',
'age': 21
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys,
values=values)
#INSERT INTO students(id, name, age) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE
update = ','.join([" {key} = %s".format(key=key) for key in data])
sql += update
#INSERT INTO students(id, name, age) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE id = %s, name = %s, age = %s
try:
if cursor.execute(sql, tuple(data.values()) * 2):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close() - 删除数据
import pymysql
table = 'students'
condition = 'age > 20'
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'DELETE FROM {table} WHERE {condition}'.format(table=table, condition=condition)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close() - 查询数据
逐行读取(注意游标类似全局变量)import pymysql
sql = 'SELECT * FROM students WHERE age >= 20'
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
try:
cursor.execute(sql)
print('Count:', cursor.rowcount)
row = cursor.fetchone()
# results = cursor.fetchall()
while row:
print('Row:', row)
row = cursor.fetchone()
except:
print('Error')
非关系型数据库存储
NoSQL,全称Not Only SQL,意为不仅仅是SQL,泛指非关系型数据库。NoSQL是基于键值对的,且不需要经过SQL层的解析,数据之间没有耦合性,性能非常高。
非关系型数据库又可细分如下。
- 键值存储数据库:代表有Redis、Voldemort和Oracle BDB等。
- 列存储数据库:代表有Cassandra、HBase和Riak等。
- 文档型数据库:代表有CouchDB和MongoDB等。
- 图形数据库:代表有Neo4J、lnfoGrid和Infinite Graph等。
对于爬虫的数据存储来说一条数据可能存在某些字段提取失败而缺失的情况,而且数据可能随时调整。另外,数据之间还存在嵌套关系。如果使用关系型数据库存储,一是需要提前建表,二是如果存在数据嵌套关系的话,需要进行序列化操作才可以存储,非常不方便。如果用了非关系型数据库,就可以避免一些麻烦,更简单高效。
MongoDB存储
MongoDB 是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,字段值可以包含其他文档、数组及文档数组,非常灵活。
相关链接:
- GitHub: https://github.com/mongodb/mongo-python-driver
- 官方文档:https://api.mongodb.com/python/current/
- PyPI: https://pypi.python.org/pypi/pymongo
安装:pip install pymongo
相关操作: - 初始化
import pymongo
from pymongo import MongoClient
#连接MongoDB
client = pymongo.MongoClient(host='localhost', port=27017)
# client = MongoClient('mongodb://localhost:27017/')
#指定数据库
db = client.test
# db = client['test']
#指定集合
collection = db.students
# collection = db['students'] - 插入数据
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
#insert返回一个ObjectId类型的_id值
result = collection.insert(student1)
result = collection.insert([student1, student2])
#官方推荐使用更加严格的方法
#返回的是InsertOneResult对象
result = collection.insert_one(student1)
print(result.inserted_id)
#返回的是InsertManyResult对象
result = collection.insert_many([student1, student2])
print(result.inserted_ids) - 查询比较符号表如下:
查询单条数据
result = collection.find_one({'name': 'Mike'})
# 根据ObjectId查询
from bson.objectid import ObjectId
result = collection.find_one({'_id': ObjectId('593278c115c2602667ec6bae')})
# 多条数据查询
results = collection.find({'age': 20}) #返回Cursor类型,相当于生成器
for result in results:
print(result)
# 条件查询
results = collection.find({'age': {'$gt': 20}})
# 正则匹配查询
results = collection.find({'age': {'$Regex': '^M.*'}})
功能符号表如下:
- 计数
count = collection.find('age': 20}).count()
- 排序
results = collection.find().sort('name', pymongo.ASCENDING)
- 偏移
# 偏移2,忽略前两个元素,得到第三个及以后的元素
results = collection.find().sort('name', pymongo.ASCENDING).skip(2)
# 指定个数
results = collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
#数据量大时采用以下办法
collection.find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}}) - 更新
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 25
# 返回结果是字典形式,ok代表执行成功,nModified代表影响的数据条数
result = collection.update(condition, student)
# 只更新该字段,不影响其他已存在字段
result = collection.update_one(condition, {'$set': student})
print(result.matched_count, result.modified_count) - 删除
result = collection.remove({'name': 'Kevin'})
result = collection.delete_one({'name': 'Kevin'})
result = collection.delete_many({'age': {'$lt': 25}})
print(result.deleted_count) - 其他操作
- 另外,PyMongo还提供了一些组合方法,如find_one_and_delete()、find one and_replace()和find_one_and_update(),它们是查找后删除、替换和更新操作,其用法与上述方法基本一致。
- 还可以对索引进行操作,相关方法有create_index()、create_indexes()和drop_index()等。
- 关于PyMongo的详细用法,可以参见官方文档:
http://api.mongodb.com/python/current/api/pymongo/collection.html - 另外,还有对数据库和集合本身等的一些操作,可以参见官方文档:
http://api.mongodb.com/python/current/api/pymongo
Redis存储
GitHub: https://github.com/andymccurdy/redis-py
官方文档:https://redis-py.readthedocs.io/
- 初始化或
from redis import StrictRedis
redis = StrictRedis(host='localhost', port=6379, db=0, password='foobared')
redis.set('name', 'Bob')
print(redis.get('name'))from redis import StrictRedis, ConnectionPool
pool = ConnectionPool(host='localhost', port=6379, db=0, password='foobared')
redis = StrictRedis(connection_pool=pool)
# 通过URL构建pool
url = 'redis://:foobared@localhost:6379/0'
pool = ConnectionPool.from_url(url)
redis = StrictRedis(connection_pool=pool) - 键操作
- 字符串操作
- 列表操作
- 散列操作
- 集合操作
- 有序集合操作
- RedisDump
- redis-dump
- redis-load
Ch 5 Ajax数据爬取
什么是Ajax
Ajax分析方法
Ajax结果提取
分析Ajax爬取今日头条节拍美图
Ch 6 动态渲染页面爬取
Selenium的使用
基本使用
from selenium import webdriver |
浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页。
声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。另外,也支持无界面浏览器 PhantomJS。用如下方式初始化:
from selenium import webdriver |
访问页面
可以用 get() 方法来请求网页,参数传入链接 URL 即可。比如,这里用 get() 方法访问淘宝,然后打印出源代码,代码如下:
from selenium import webdriver |
查找节点
- 单个节点
比如,find_element_by_name()是根据 name 值获取,find_element_by_id()是根据 id 获取。另外,还有根据 XPath、CSS 选择器等获取的方式。
代码实现:这里列出所有获取单个节点的方法:from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()另外,Selenium 还提供了通用方法find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selectorfind_element(),它需要传入两个参数:查找方式 By 和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。示例:input_first = browser.find_element(By.ID, 'q')
- 多个节点
使用find_elements(),示例:得到的内容变成了列表类型,列表中的每个节点都是from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()WebElement类型。
这里列出所有获取多个节点的方法:也可以直接用 find_elements() 方法来选择,这时可以这样写:find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selectorlis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys() 方法,清空文字时用 clear() 方法,点击按钮时用 click() 方法。示例如下:
from selenium import webdriver |
更多的操作可以参见官方文档的交互动作介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement。
动作链
另外一些操作,没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver |
更多的动作链操作参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains。
执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
from selenium import webdriver |
获取节点信息
- 获取属性
使用 get_attribute() 方法来获取节点的属性,示例如下:from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class')) - 获取文本值
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于 Beautiful Soup 的get_text()方法、pyquery 的text()方法,示例如下:from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text) - 获取 id、位置、标签名和大小
示例如下:from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)切换 Frame
网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。示例如下:import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
延时等待
隐式等待
当使用隐式等待执行测试的时候,如果 Selenium 没有在 DOM 中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。示例如下:from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)显式等待
指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)这里首先引入 WebDriverWait 这个对象,指定最长等待时间,然后调用它的 until() 方法,传入要等待条件 expected_conditions。比如,这里传入了 presence_of_element_located 这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是 ID 为 q 的节点搜索框。
这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为 element_to_be_clickable,也就是可点击,所以查找按钮时查找 CSS 选择器为.btn-search 的按钮,如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常。
等待条件还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。如下所示:

更多等待条件的参数及用法,参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions。
前进和后退
示例如下:
import time |
Cookies
获取、添加、删除 Cookies 等。示例如下:
from selenium import webdriver |
选项卡管理
示例如下:
import time |
异常处理
节点未找到的异常,示例如下:
from selenium import webdriver |
更多的异常类,可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions。
Chrome Headless 模式
从 Chrome 59 版本开始,已经开始支持 Headless 模式,也就是无界面模式,这样爬取的时候就不会弹出浏览器了。如果要使用此模式,请把 Chrome 升级到 59 版本及以上。启用 Headless 模式的方式如下:
chrome_options = webdriver.ChromeOptions() |
Splash的使用
Splash是一个JavaScript渲染服务,是一个带有HTTP API的轻量级浏览器,同时对接了Python中的Twisted和QT库。
安装运行:
docker run -p 8050:8050 scrapinghub/splash |
以守护态运行:
docker run -d -p 8050:8050 scrapinghub/splash |
Splash 使用未绑定的内存缓冲,因此它最终会占用所有的内存。一个解决的办法是在它占用过量内存时进行重启。 Splash中的 –maxrss 参数正是这个作用。您还可以在Docker中添加 –memory 选项。
在正式产品中固定使用同一个版本的Splash会是一个好的做法。相比于使用 scrapinghub/splash 来说 使用像 scrapinghub/splash:2.0 这样的可能会更好
如果您希望设置Splash使用的最大内存为4GB,并且加上守护进程,崩溃重启这些特性,您可以使用下面的命令
docker run -d -p 8050:8050 --memory=4.5G --restart=always scrapinghub/splash:3.5 --maxrss 4000 |
当然,您可能需要一个负载均衡。这样您可以在Splash中进行与Aquarium或者HAProxy 相关的配置
功能介绍
- 利用Splash,可以实现如下功能:
- 异步方式处理多个网页渲染过程;
- 获取渲染后的页面的源代码或截图;
- 通过关闭图片渲染或者使用Adblock规则来加快页面渲染速度;
- 可执行特定的JavaScript脚本;
- 可通过Lua脚本来控制页面渲染过程;
- 获取渲染的详细过程并通过HAR(HTTP Archive)格式呈现。
Splash Lua脚本
Splash可以通过Lua脚本执行一系列渲染操作,这样我们就可以用Splash来模拟类似Chrome、PhantomJS的操作了。
入口及返回值
实例:function main(splash, args)
splash:go("http://www.baidu.com")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return {title=title}
end
Output:
Splash Response: Object
title: "百度一下,你就知道"通过evaljs()方法传人JavaScript脚本,而document.title的执行结果就是返回网页标题,执行完毕后将其赋值给一个title变盘,随后将其返回。
main()方法名称必须是固定的,Splash会默认调用这个方法。该方法的返回值既可以是字典形式,也可以是字符串形式,最后都会转化为Splash HTTP Response。异步处理
实例:function main(splash, args)
local example_urls = {"www.baidu.com", "www.taobao.com", "www.zhihu.com"}
local urls = args.urls or example_urls
local results = {}
for index, url in ipairs(urls) do
local ok, reason = splash:go("http://" .. url)
if ok then
splash:wait(2)
results[url] = splash:png()
end
end
return results
end运行结果是三个站点的截图。
在脚本内调用的wait()方法类似于Python中的sleep(),其参数为等待的秒数。当 Splash 执行到此方法时,它会转而去处理其他任务,然后在指定的时间过后再回来继续处理。这里值得注意的是,Lua 脚本中的字符串拼接和 Python 不同,它使用的是
..操作符,而不是+。如果有必要,可以简单了解一下 Lua 脚本的语法,详见:http://www.runoob.com/lua/lua-basic-syntax.html另外,这里做了加载时的异常检测。
go()方法会返回加载页面的结果状态,如果页面出现 4xx 或 5xx 状态码,ok变量就为空,就不会返回加载后的图片。
Splash对象属性
args
该属性可以获取加载时配置的参数,比如 URL,如果为 GET 请求,它还可以获取 GET 请求参数;如果为 POST 请求,它可以获取表单提交的数据。Splash 也支持使用第二个参数直接作为 args,例如:function main(splash, args)
local url = args.url
--local url = splash.args.url --两者等价
endjs_enabled
Splash的 JavaScript 执行开关,可以将其配置为 true 或 false 来控制是否执行 JavaScript 代码,默认为 true。示例:function main(splash, args)
splash:go("https://www.baidu.com")
splash.js_enabled = false
local title = splash:evaljs("document.title")
return {title=title}
end此时运行结果就会抛出异常,一般来说,不用设置此属性,默认开启即可。
resource_timeout
设置加载的超时时间,单位为秒。如果设置为 0 或 nil(类似 Python 中的 None),代表不检测超时。
这里将超时时间设置为 0.1 秒。如果在 0.1 秒之内没有得到响应,就会抛出异常,示例如下:function main(splash)
splash.resource_timeout = 0.1
assert(splash:go('https://www.taobao.com'))
return splash:png()
endimages_enabled
设置图片是否加载,默认情况下是加载的。禁用该属性后,可以节省网络流量并提高网页加载速度。但是需要注意的是,禁用图片加载可能会影响 JavaScript 渲染。因为禁用图片之后,它的外层 DOM 节点的高度会受影响,进而影响 DOM 节点的位置。因此,如果 JavaScript 对图片节点有操作的话,其执行就会受到影响。另外,Splash 使用了缓存。如果一开始加载出来了网页图片,然后禁用了图片加载,再重新加载页面,之前加载好的图片可能还会显示出来,这时直接重启 Splash 即可。
禁用图片加载的示例如下:
function main(splash, args)
splash.images_enabled = false
assert(splash:go('https://www.jd.com'))
return {png=splash:png()}
endplugins_enabled
控制浏览器插件(如 Flash 插件)是否开启。默认情况下,此属性是 false,表示不开启。可以使用如下代码控制其开启和关闭:splash.plugins_enabled = true/false
scroll_position
控制页面上下或左右滚动。示例如下:function main(splash, args)
assert(splash:go('https://www.taobao.com'))
splash.scroll_position = {x=100, y=400}
return {png=splash:png()}
end
Splash对象的方法
官方文档:https://splash.readthedocs.io/en/stable/scripting-ref.html,
针对页面元素的 API 操作: https://splash.readthedocs.io/en/stable/scripting-element-object.html。
go()
用来请求某个链接,可以模拟 GET 和 POST 请求,同时支持传入请求头、表单等数据,其用法如下:ok, reason = splash:go{url, baseurl=nil, headers=nil, http_method="GET", body=nil, formdata=nil}
参数说明如下。
url:请求的 URL。baseurl:可选参数,默认为空,表示资源加载相对路径。headers:可选参数,默认为空,表示请求头。http_method:可选参数,默认为 GET,同时支持 POST。body:可选参数,默认为空,发 POST 请求时的表单数据,使用的 Content-type 为 application/json。formdata:可选参数,默认为空,POST 的时候的表单数据,使用的 Content-type 为 application/x-www-form-urlencoded。
该方法的返回结果是结果 ok 和原因 reason 的组合,如果 ok 为空,代表网页加载出现了错误,此时 reason 变量中包含了错误的原因,否则证明页面加载成功。示例如下:
function main(splash, args)
local ok, reason = splash:go{"http://httpbin.org/post", http_method="POST", body="name=Germey"}
if ok then
return splash:html()
end
endwait()
控制页面的等待时间,使用方法如下:ok, reason = splash:wait{time, cancel_on_redirect=false, cancel_on_error=true}
参数说明如下。
- time:等待的秒数。
- cancel_on_redirect:可选参数,默认为 false,表示如果发生了重定向就停止等待,并返回重定向结果。
- cancel_on_error:可选参数,默认为 false,表示如果发生了加载错误,就停止等待。
返回结果同样是结果 ok 和原因 reason 的组合。示例如下:
function main(splash)
splash:go("https://www.taobao.com")
splash:wait(2)
return {html=splash:html()}
endjsfunc()
可以直接调用 JavaScript 定义的方法,但是所调用的方法需要用双中括号包围,相当于实现了 JavaScript 方法到 Lua 脚本的转换。示例如下:function main(splash, args)
local get_div_count = splash:jsfunc([[
function () {
var body = document.body;
var divs = body.getElementsByTagName('div');
return divs.length;
}
]])
splash:go("https://www.baidu.com")
return ("There are %s DIVs"):format(
get_div_count())
end关于 JavaScript 到 Lua 脚本的更多转换细节,可以参考官方文档:https://splash.readthedocs.io/en/stable/scripting-ref.html#splash-jsfunc。
evaljs()
执行 JavaScript 代码并返回最后一条 JavaScript 语句的返回结果,使用方法如下:local title = splash:evaljs("document.title")
runjs()
执行 JavaScript 代码,与 evaljs() 的功能类似,但是更偏向于执行某些动作或声明某些方法。例如:function main(splash, args)
splash:go("https://www.baidu.com")
splash:runjs("foo = function() { return 'bar' }")
local result = splash:evaljs("foo()")
return result
endautoload()
设置每个页面访问时自动加载的对象,使用方法如下:ok, reason = splash:autoload{source_or_url, source=nil, url=nil}
参数说明如下。
- source_or_url:JavaScript 代码或者 JavaScript 库链接。
- source:JavaScript 代码。
- url:JavaScript 库链接
但是此方法只负责加载 JavaScript 代码或库,不执行任何操作。如果要执行操作,可以调用 evaljs() 或 runjs() 方法。示例如下:
function main(splash, args)
splash:autoload([[
function get_document_title(){
return document.title;
}
]])
splash:go("https://www.baidu.com")
return splash:evaljs("get_document_title()")
end使用 autoload() 方法加载某些方法库,如 jQuery,示例如下:
function main(splash, args)
assert(splash:autoload("https://code.jquery.com/jquery-2.1.3.min.js"))
assert(splash:go("https://www.taobao.com"))
local version = splash:evaljs("$.fn.jquery")
return 'JQuery version: ' .. version
endcall_later()
通过设置定时任务和延迟时间来实现任务延时执行,并且可以在执行前通过 cancel() 方法重新执行定时任务。示例如下:function main(splash, args)
local snapshots = {}
local timer = splash:call_later(function()
snapshots["a"] = splash:png()
splash:wait(1.0)
snapshots["b"] = splash:png()
end, 0.2)
splash:go("https://www.taobao.com")
splash:wait(3.0)
return snapshots
end这里设置了一个定时任务,0.2 秒的时候获取网页截图,然后等待 1 秒,1.2 秒时再次获取网页截图,第一次截图时网页还没有加载出来,截图为空,第二次网页便加载成功了。
http_get()
模拟发送 HTTP 的 GET 请求,使用方法如下:response = splash:http_get{url, headers=nil, follow_redirects=true}
参数说明如下。
- url:请求 URL。
- headers:可选参数,默认为空,请求头。
- follow_redirects:可选参数,表示是否启动自动重定向,默认为 true。
示例如下:
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
endhttp_post()
模拟发送 POST 请求,多了一个参数 body,使用方法如下:response = splash:http_post{url, headers=nil, follow_redirects=true, body=nil}
示例:
function main(splash, args)
local treat = require("treat")
local json = require("json")
local response = splash:http_post{"http://httpbin.org/post",
body=json.encode({name="Germey"}),
headers={["content-type"]="application/json"}
}
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
endset_content()
设置页面的内容,示例如下:function main(splash)
assert(splash:set_content("<html><body><h1>hello</h1></body></html>"))
return splash:png()
endhtml()
用来获取网页的源代码,示例如下:function main(splash, args)
splash:go("https://httpbin.org/get")
return splash:html()
endpng()
用来获取 PNG 格式的网页截图,示例如下:function main(splash, args)
splash:go("https://www.taobao.com")
return splash:png()
endjpeg()
来获取 JPEG 格式的网页截图,示例如下:function main(splash, args)
splash:go("https://www.taobao.com")
return splash:jpeg()
endhar()
用来获取页面加载过程描述,示例如下:function main(splash, args)
splash:go("https://www.baidu.com")
return splash:har()
endurl()
获取当前正在访问的 URL,示例如下:function main(splash, args)
splash:go("https://www.baidu.com")
return splash:url()
endget_cookies()
获取当前页面的 Cookies,示例如下:function main(splash, args)
splash:go("https://www.baidu.com")
return splash:get_cookies()
endadd_cookie()
为当前页面添加 Cookie,用法如下:cookies = splash:add_cookie{name, value, path=nil, domain=nil, expires=nil, httpOnly=nil, secure=nil}
该方法的各个参数代表 Cookie 的各个属性。示例如下:
function main(splash)
splash:add_cookie{"sessionid", "237465ghgfsd", "/", domain="http://example.com"}
splash:go("http://example.com/")
return splash:html()
endclear_cookies()
清除所有的 Cookies,示例如下:function main(splash)
splash:go("https://www.baidu.com/")
splash:clear_cookies()
return splash:get_cookies()
endget_viewport_size()
获取当前浏览器页面的大小,即宽高,示例如下:function main(splash)
splash:go("https://www.baidu.com/")
return splash:get_viewport_size()
endset_viewport_size()
设置当前浏览器页面的大小,即宽高,用法如下:function main(splash)
splash:set_viewport_size(400, 700)
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
endset_viewport_full()
设置浏览器全屏显示,示例如下:function main(splash)
splash:set_viewport_full()
assert(splash:go("http://cuiqingcai.com"))
return splash:png()
endset_user_agent()
设置浏览器的 User-Agent,示例如下:function main(splash)
splash:set_user_agent('Splash')
splash:go("http://httpbin.org/get")
return splash:html()
endset_custom_headers()
设置请求头,示例如下:function main(splash)
splash:set_custom_headers({
["User-Agent"] = "Splash",
["Site"] = "Splash",
})
splash:go("http://httpbin.org/get")
return splash:html()
endselect()
选中符合条件的第一个节点,如果有多个节点符合条件,则只会返回一个,其参数是 CSS 选择器。示例如下:function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
splash:wait(3)
return splash:png()
end这里首先访问了百度,然后选中了搜索框,随后调用了 send_text() 方法填写了文本,然后返回网页截图。
select_all()
选中所有符合条件的节点,其参数是 CSS 选择器。示例如下:function main(splash)
local treat = require('treat')
assert(splash:go("http://quotes.toscrape.com/"))
assert(splash:wait(0.5))
local texts = splash:select_all('.quote .text')
local results = {}
for index, text in ipairs(texts) do
results[index] = text.node.innerHTML
end
return treat.as_array(results)
endmouse_click()
模拟鼠标点击操作,传入的参数为坐标值 x 和 y。此外,也可以直接选中某个节点,然后调用此方法,示例如下:function main(splash)
splash:go("https://www.baidu.com/")
input = splash:select("#kw")
input:send_text('Splash')
submit = splash:select('#su')
submit:mouse_click()
splash:wait(3)
return splash:png()
end这里首先选中页面的输入框,输入了文本,然后选中 “提交” 按钮,调用了 mouse_click() 方法提交查询,然后页面等待三秒,返回截图。
Splash API调用
和 Python 程序结合使用并抓取 JavaScript 渲染的页面, Splash 提供了一些 HTTP API 接口,只需要请求这些接口并传递相应的参数即可,下面简要介绍这些接口。
render.html
此接口用于获取 JavaScript 渲染的页面的 HTML 代码,接口地址就是 Splash 的运行地址加此接口名称,例如 http://localhost:8050/render.html。Python 实现代码如下:import requests
url = 'http://localhost:8050/render.html?url=https://www.baidu.com'
response = requests.get(url)
print(response.text)此接口还可以指定其他参数,比如通过 wait 指定等待秒数。如果要确保页面完全加载出来,可以增加等待时间,例如:
url = 'http://localhost:8050/render.html?url=https://www.taobao.com&wait=5'另外,此接口还支持代理设置、图片加载设置、Headers 设置、请求方法设置,具体的用法可以参见官方文档 https://splash.readthedocs.io/en/stable/api.html#render-html。
render.png
此接口可以获取网页截图,其参数比 render.html 多了几个,比如通过 width 和 height 来控制宽高,返回的是 PNG 格式的图片二进制数据。示例如下:curl http://localhost:8050/render.png?url=https://www.taobao.com&wait=5&width=1000&height=700
Python 实现,可以将返回的二进制数据保存为 PNG 格式的图片,具体如下:
import requests
url = 'http://localhost:8050/render.png?url=https://www.jd.com&wait=5&width=1000&height=700'
response = requests.get(url)
with open('taobao.png', 'wb') as f:
f.write(response.content)详细的参数设置可以参考官网文档 https://splash.readthedocs.io/en/stable/api.html#render-png。
render.jpeg
此接口和 render.png 类似,不过它返回的是 JPEG 格式的图片二进制数据。另外,此接口比 render.png 多了参数 quality,它用来设置图片质量。
render.har
此接口用于获取页面加载的 HAR 数据,示例如下:curl http://localhost:8050/render.har?url=https://www.jd.com&wait=5
它的返回结果非常多,是一个 JSON 格式的数据,其中包含页面加载过程中的 HAR 数据。
render.json
此接口包含了前面接口的所有功能,返回结果是 JSON 格式,通过传入不同参数控制其返回结果。比如,传入 html=1,返回结果即会增加源代码数据;传入 png=1,返回结果即会增加页面 PNG 截图数据;传入 har=1,则会获得页面 HAR 数据。例如:curl http://localhost:8050/render.json?url=https://httpbin.org&html=1&har=1
更多参数设置,具体可以参考官方文档:https://splash.readthedocs.io/en/stable/api.html#render-json。
execute
此接口是最为强大的接口。前面说了很多 Splash Lua 脚本的操作,用此接口便可实现与 Lua 脚本的对接。前面的 render.html 和 render.png 等接口对于一般的 JavaScript 渲染页面是足够了,但是如果要实现一些交互操作的话,它们还是无能为力,这里就需要使用 execute 接口了。
通过 lua_source 参数传递了转码后的 Lua 脚本,通过 execute 接口获取了最终脚本的执行结果。Python 实现代码如下:
import requests
from urllib.parse import quote
lua = '''
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return {
html=treat.as_string(response.body),
url=response.url,
status=response.status
}
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua)
response = requests.get(url)
print(response.text)
Splash负载均衡配置
用 Splash 做页面抓取时,如果爬取的量非常大,任务非常多,用一个 Splash 服务来处理的话,压力太大了,此时可以考虑搭建一个负载均衡器来把压力分散到各个服务器上。这相当于多台机器多个服务共同参与任务的处理,可以减小单个 Splash 服务的压力。
配置 Splash 服务
配置负载均衡
选用任意一台带有公网 IP 的主机来配置负载均衡。首先,在这台主机上装好 Nginx,然后修改 Nginx 的配置文件 nginx.conf,添加如下内容:http {
upstream splash {
least_conn;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
server {
listen 8050;
location / {
proxy_pass http://splash;
}
}
}通过 upstream 字段定义了一个名字叫作 splash 的服务集群配置。其中 least_conn 代表最少链接负载均衡,它适合处理请求处理时间长短不一造成服务器过载的情况。不指定配置,默认以轮询策略实现负载均衡,每个服务器的压力相同。此策略适合服务器配置相当、无状态且短平快的服务使用。
另外,还可以指定权重,配置如下:upstream splash {
server 41.159.27.223:8050 weight=4;
server 41.159.27.221:8050 weight=2;
server 41.159.27.9:8050 weight=2;
server 41.159.117.119:8050 weight=1;
}最后,还有一种 IP 散列负载均衡,配置如下:
upstream splash {
ip_hash;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}服务器根据请求客户端的 IP 地址进行散列计算,确保使用同一个服务器响应请求,这种策略适合有状态的服务,比如用户登录后访问某个页面的情形。对于 Splash 来说,不需要应用此设置。
可以根据不同的情形选用不同的配置,配置完成后重启一下 Nginx 服务:
sudo nginx -s reload配置认证
现在 Splash 是可以公开访问的,如果不想让其公开访问,还可以配置认证,这仍然借助于 Nginx。可以在 server 的 location 字段中添加 auth_basic 和 auth_basic_user_file 字段,具体配置如下:http {
upstream splash {
least_conn;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
server {
listen 8050;
location / {
proxy_pass http://splash;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}这里使用的用户名和密码配置放置在 /etc/nginx/conf.d 目录下,我们需要使用 htpasswd 命令创建。例如,创建一个用户名为 admin 的文件,相关命令如下:
htpasswd -c .htpasswd admin
配置完成后,重启一下 Nginx 服务。测试
利用 http://httpbin.org/get 测试即可,实现代码如下:import requests
from urllib.parse import quote
import re
lua = '''
function main(splash, args)
local treat = require("treat")
local response = splash:http_get("http://httpbin.org/get")
return treat.as_string(response.body)
end
'''
url = 'http://splash:8050/execute?lua_source=' + quote(lua)
response = requests.get(url, auth=('admin', 'admin'))
ip = re.search('(\d+\.\d+\.\d+\.\d+)', response.text).group(1)
print(ip)
使用Selenium爬取淘宝商品
Ch 7 验证码的识别
图形验证码识别
滑动验证码识别
点触验证码识别
宫格验证码识别
Ch 8 代理的使用
代理的设置
urllib
from urllib.error import URLError |
SOCKS5代理:
|
requests
import requests |
SOCKS5代理:
# pip install 'requests[socks]' |
或:
import requests |
Selenium
- Chrome认证代理:
from selenium import webdriver
proxy = '127.0.0.1:9743'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + proxy)
chrome = webdriver.Chrome(chrome_options=chrome_options)
chrome.get('http://httpbin.org/get')
需要在本地创建一个manifest.json配置文件和background脚本来设置认证代理。运行代码之后本地会生成一个proxy_auth__plugin.zip文件来保存当前配置。from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import zipfile
ip = '127.0.0.1'
port = 9743
username = 'foo'
password = 'bar'
manifest_json = """
{
"version": "1.0.0",
"manifest_version": 2,
"name": "Chrome Proxy",
"permissions": [
"proxy",
"tabs",
"unlimitedStorage",
"storage",
"<all_urls>",
"webRequest",
"webRequestBlocking"
],
"background": {
"scripts": ["background.js"]
}
}
"""
background_js = """
var config = {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "http",
host: "%(ip)s",
port: %(port)s
}
}
}
chrome.proxy.settings.set({value: config, scope: "regular"}, function() {});
function callbackFn(details) {
return {
authCredentials: {
username: "%(username)s",
password: "%(password)s"
}
}
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{urls: ["<all_urls>"]},
['blocking']
)
""" % {'ip': ip, 'port': port, 'username': username, 'password': password}
plugin_file = 'proxy_auth_plugin.zip'
with zipfile.ZipFile(plugin_file, 'w') as zp:
zp.writestr("manifest.json", manifest_json)
zp.writestr("background.js", background_js)
chrome_options = Options()
chrome_options.add_argument("--start-maximized")
chrome_options.add_extension(plugin_file)
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://httpbin.org/get') - PhatomJS
from selenium import webdriver
service_args = [
'--proxy=127.0.0.1:9743',
'--proxy-type=http'
]
# 认证代理
# service_args = [
# '--proxy=127.0.0.1:9743',
# '--proxy-type=http',
# '--proxy-auth=username:password'
# ]
browser = webdriver.PhantomJS(service_args=service_args)
browser.get('http://httpbin.org/get')
print(browser.page_source)
代理池的维护
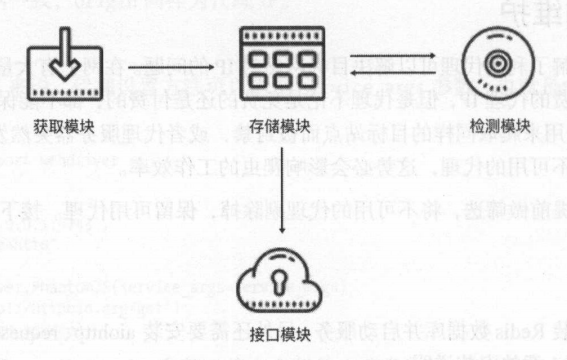
基本架构
代理池分为4个模块:存储模块、获取模块、检测模块和接口模块。
- 存储模块
存储模块使用Redis的有序集合,用来做代理的去重和状态标识,同时它也是中心模块和基础模块,将其他模块串联起来。 - 获取模块
获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库。 - 检测模块
检测模块定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识。 - 接口模块
接口模块通过WebAPI提供服务接口,接口通过连接数据库并通过Web形式返回可用的代理。
实现
参考项目地址:https://github.com/Python3WebSpider/ProxyPool
存储模块
对于代理池来说,有序集合中每个元素的分数可以作为判断一个代理是否可用的标志,100为最高分,代表最可用,0为最低分,代表最不可用。如果要获取可用代理,可以从代理池中随机获取分数最高的代理。
设置分数规则如下:- 分数100为可用,检测器会定时循环检测每个代理可用情况,一旦检测到有可用的代理就立即置为100,检测到不可用就将分数减1,分数减至0后代理移除。
- 新获取的代理的分数为10,如果测试可行,分数立即置为100,不可行则分数减1,分数减至0后代理移除。
import redis
from proxypool.exceptions import PoolEmptyException
from proxypool.schemas.proxy import Proxy
from proxypool.setting import REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, REDIS_DB, REDIS_KEY
from proxypool.setting import PROXY_SCORE_MAX, PROXY_SCORE_MIN, PROXY_SCORE_INIT
from random import choice
from typing import List
from loguru import logger
from proxypool.utils.proxy import is_valid_proxy, convert_proxy_or_proxies
REDIS_CLIENT_VERSION = redis.__version__
IS_REDIS_VERSION_2 = REDIS_CLIENT_VERSION.startswith('2.')
class RedisClient(object):
"""
redis connection client of proxypool
"""
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD, db=REDIS_DB, **kwargs):
"""
init redis client
:param host: redis host
:param port: redis port
:param password: redis password
"""
self.db = redis.StrictRedis(host=host, port=port, password=password, db=db, decode_responses=True, **kwargs)
# 函数参数中的冒号是参数的类型建议符,告诉程序员希望传入的实参的类型。
# 函数后面跟着的箭头是函数返回值的类型建议符,用来说明该函数返回的值是什么类型。
def add(self, proxy: Proxy, score=PROXY_SCORE_INIT) -> int:
"""
add proxy and set it to init score
:param proxy: proxy, ip:port, like 8.8.8.8:88
:param score: int score
:return: result
"""
if not is_valid_proxy(f'{proxy.host}:{proxy.port}'):
logger.info(f'invalid proxy {proxy}, throw it')
return
if not self.exists(proxy):
if IS_REDIS_VERSION_2:
return self.db.zadd(REDIS_KEY, score, proxy.string())
return self.db.zadd(REDIS_KEY, {proxy.string(): score})
def random(self) -> Proxy:
"""
get random proxy
firstly try to get proxy with max score
if not exists, try to get proxy by rank
if not exists, raise error
:return: proxy, like 8.8.8.8:8
"""
# try to get proxy with max score
proxies = self.db.zrangebyscore(REDIS_KEY, PROXY_SCORE_MAX, PROXY_SCORE_MAX)
if len(proxies):
return convert_proxy_or_proxies(choice(proxies))
# else get proxy by rank
proxies = self.db.zrevrange(REDIS_KEY, PROXY_SCORE_MIN, PROXY_SCORE_MAX)
if len(proxies):
return convert_proxy_or_proxies(choice(proxies))
# else raise error
raise PoolEmptyException
def decrease(self, proxy: Proxy) -> int:
"""
decrease score of proxy, if small than PROXY_SCORE_MIN, delete it
:param proxy: proxy
:return: new score
"""
if IS_REDIS_VERSION_2:
self.db.zincrby(REDIS_KEY, proxy.string(), -1)
else:
self.db.zincrby(REDIS_KEY, -1, proxy.string())
score = self.db.zscore(REDIS_KEY, proxy.string())
#相当于"{}".format()
logger.info(f'{proxy.string()} score decrease 1, current {score}')
if score <= PROXY_SCORE_MIN:
logger.info(f'{proxy.string()} current score {score}, remove')
self.db.zrem(REDIS_KEY, proxy.string())
def exists(self, proxy: Proxy) -> bool:
"""
if proxy exists
:param proxy: proxy
:return: if exists, bool
"""
return not self.db.zscore(REDIS_KEY, proxy.string()) is None
def max(self, proxy: Proxy) -> int:
"""
set proxy to max score
:param proxy: proxy
:return: new score
"""
logger.info(f'{proxy.string()} is valid, set to {PROXY_SCORE_MAX}')
if IS_REDIS_VERSION_2:
return self.db.zadd(REDIS_KEY, PROXY_SCORE_MAX, proxy.string())
return self.db.zadd(REDIS_KEY, {proxy.string(): PROXY_SCORE_MAX})
def count(self) -> int:
"""
get count of proxies
:return: count, int
"""
return self.db.zcard(REDIS_KEY)
def all(self) -> List[Proxy]:
"""
get all proxies
:return: list of proxies
"""
return convert_proxy_or_proxies(self.db.zrangebyscore(REDIS_KEY, PROXY_SCORE_MIN, PROXY_SCORE_MAX))
def batch(self, cursor, count) -> List[Proxy]:
"""
get batch of proxies
:param cursor: scan cursor
:param count: scan count
:return: list of proxies
"""
cursor, proxies = self.db.zscan(REDIS_KEY, cursor, count=count)
return cursor, convert_proxy_or_proxies([i[0] for i in proxies])
if __name__ == '__main__':
conn = RedisClient()
result = conn.random()
print(result)
获取模块
获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库。# base.py
from retrying import retry
import requests
from loguru import logger
from proxypool.setting import GET_TIMEOUT
class BaseCrawler(object):
urls = []
"""
retry装饰器:
stop_max_attempt_number:在停止之前尝试的最大次数,最后一次如果还是有异常则会抛出异常,停止运行,默认为5次
wait_random_min:在两次调用方法停留时长,停留最短时间,默认为0,单位毫秒
wait_random_max:在两次调用方法停留时长,停留最长时间,默认为1000毫秒
wait_fixed:设置在两次retrying之间的停留时间
stop_max_delay:从被装饰的函数开始执行的时间点开始到函数成功运行结束或失败报错中止的时间点。单位:毫秒
retry_on_result:指定一个函数,如果指定的函数返回True,则重试,否则抛出异常退出
retry_on_exception: 指定一个函数,如果此函数返回指定异常,则会重试,如果不是指定的异常则会退出
"""
def fetch(self, url, **kwargs):
"""
获取html源码
"""
try:
kwargs.setdefault('timeout', GET_TIMEOUT)
kwargs.setdefault('verify', False)
response = requests.get(url, **kwargs)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
except requests.ConnectionError:
return
def crawl(self):
"""
crawl main method
"""
for url in self.urls:
logger.info(f'fetching {url}')
html = self.fetch(url)
for proxy in self.parse(html):
logger.info(f'fetched proxy {proxy.string()} from {url}')
yield proxy
# daili66.py
from pyquery import PyQuery
from proxypool.schemas.proxy import Proxy
from proxypool.crawlers.base import BaseCrawler
BASE_URL = 'http://www.66ip.cn/{page}.html'
MAX_PAGE = 5
# 继承BaseCrawler
class Daili66Crawler(BaseCrawler):
"""
daili66 crawler, http://www.66ip.cn/1.html
"""
urls = [BASE_URL.format(page=page) for page in range(1, MAX_PAGE + 1)]
def parse(self, html):
"""
parse html file to get proxies
:return:
"""
doc = PyQuery(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
host = tr.find('td:nth-child(1)').text()
port = int(tr.find('td:nth-child(2)').text())
yield Proxy(host=host, port=port)
if __name__ == '__main__':
crawler = Daili66Crawler()
for proxy in crawler.crawl():
print(proxy)检测模块
检测模块定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识。
这里使用异步请求库aiohttp来进行检测。import asyncio
import aiohttp
from loguru import logger
from proxypool.schemas import Proxy
from proxypool.storages.redis import RedisClient
from proxypool.setting import TEST_TIMEOUT, TEST_BATCH, TEST_URL, TEST_VALID_STATUS, TEST_ANONYMOUS
from aiohttp import ClientProxyConnectionError, ServerDisconnectedError, ClientOSError, ClientHttpProxyError
from asyncio import TimeoutError
EXCEPTIONS = (
ClientProxyConnectionError,
ConnectionRefusedError,
TimeoutError,
ServerDisconnectedError,
ClientOSError,
ClientHttpProxyError,
AssertionError
)
class Tester(object):
"""
tester for testing proxies in queue
"""
def __init__(self):
"""
init redis
"""
self.redis = RedisClient()
self.loop = asyncio.get_event_loop()
async def test(self, proxy: Proxy):
"""
test single proxy
:param proxy: Proxy object
:return:
"""
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as session:
try:
logger.debug(f'testing {proxy.string()}')
# if TEST_ANONYMOUS(匿名) is True, make sure that
# the proxy has the effect of hiding the real IP
if TEST_ANONYMOUS:
url = 'https://httpbin.org/ip'
async with session.get(url, timeout=TEST_TIMEOUT) as response:
resp_json = await response.json()
origin_ip = resp_json['origin']
async with session.get(url, proxy=f'http://{proxy.string()}', timeout=TEST_TIMEOUT) as response:
resp_json = await response.json()
anonymous_ip = resp_json['origin']
assert origin_ip != anonymous_ip
assert proxy.host == anonymous_ip
async with session.get(TEST_URL, proxy=f'http://{proxy.string()}', timeout=TEST_TIMEOUT,
allow_redirects=False) as response:
if response.status in TEST_VALID_STATUS:
self.redis.max(proxy)
logger.debug(f'proxy {proxy.string()} is valid, set max score')
else:
self.redis.decrease(proxy)
logger.debug(f'proxy {proxy.string()} is invalid, decrease score')
except EXCEPTIONS:
self.redis.decrease(proxy)
logger.debug(f'proxy {proxy.string()} is invalid, decrease score')
def run(self):
"""
test main method
:return:
"""
# event loop of aiohttp
logger.info('stating tester...')
count = self.redis.count()
logger.debug(f'{count} proxies to test')
cursor = 0
while True:
logger.debug(f'testing proxies use cursor {cursor}, count {TEST_BATCH}')
cursor, proxies = self.redis.batch(cursor, count=TEST_BATCH)
if proxies:
tasks = [self.test(proxy) for proxy in proxies]
self.loop.run_until_complete(asyncio.wait(tasks))
if not cursor:
break
if __name__ == '__main__':
tester = Tester()
tester.run()接口模块
接口模块通过WebAPI提供服务接口,接口通过连接数据库并通过Web形式返回可用的代理。from flask import Flask, g
from proxypool.storages.redis import RedisClient
from proxypool.setting import API_HOST, API_PORT, API_THREADED
__all__ = ['app']
app = Flask(__name__)
def get_conn():
"""
get redis client object
:return:
"""
if not hasattr(g, 'redis'):
g.redis = RedisClient()
return g.redis
def index():
"""
get home page, you can define your own templates
:return:
"""
return '<h2>Welcome to Proxy Pool System</h2>'
def get_proxy():
"""
get a random proxy
:return: get a random proxy
"""
conn = get_conn()
return conn.random().string()
def get_count():
"""
get the count of proxies
:return: count, int
"""
conn = get_conn()
return str(conn.count())
if __name__ == '__main__':
app.run(host=API_HOST, port=API_PORT, threaded=API_THREADED)
运行
pipenv shell |
程序对接实现:
import requests |
付费代理的使用
ADSL拨号代理
ADSL(Asymmetric Digital Subscriber Line,非对称数字用户环路),它的上行和下行带宽不对称,采用频分复用技术把普通的电话线分成了电话、上行和下行3个相对独立的信道,从而避免了相互之间的干扰。
ADSL通过拨号的方式上网,需要输入ADSL账号和密码,每次拨号就更换一个IP。IP分布在多个A段,如果IP都能使用,则意味着E量级可达千万。如果我们将ADSL主机作为代理,每隔一段时间主机拨号就换一个IP,这样可以有效防止IP被封禁。另外,主机的稳定性很好,代理响应速度很快。
参考项目:https://github.com/Python3WebSpider/AdslProxy
- 准备工作
- 设置代理服务器
- 动态获取IP
- 存储模块
- 拨号模块
- 接口模块
使用代理爬取微信公众号文章
参考项目:https://github.com/Python3WebSpider/Weixin
- 主要实现功能:
- 修改代理池检测链接为搜狗微信站点。
- 构造Redis爬取队列,用队列实现请求的存取。
- 实现异常处理,失败的请求重新加入队列 。
- 实现翻页和提取文章列表,并把对应请求加入队列。
- 实现微信文章的信息的提取。
- 将提取到的信息保存到MySQL。
- 构造请求
from weixin.config import *
from requests import Request
class WeixinRequest(Request):
def __init__(self, url, callback, method='GET', headers=None, need_proxy=False, fail_time=0, timeout=TIMEOUT):
# 调用父类Request的__init__()方法
Request.__init__(self, method, url, headers)
# 添加需要的额外属性
self.callback = callback
self.need_proxy = need_proxy
self.fail_time = fail_time
self.timeout = timeout - 实现请求队列
from redis import StrictRedis
from weixin.config import *
from pickle import dumps, loads
from weixin.request import WeixinRequest
class RedisQueue():
def __init__(self):
"""
初始化Redis
"""
self.db = StrictRedis(host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD)
def add(self, request):
"""
向队列添加序列化后的Request
:param request: 请求对象
:param fail_time: 失败次数
:return: 添加结果
"""
if isinstance(request, WeixinRequest):
return self.db.rpush(REDIS_KEY, dumps(request))
return False
def pop(self):
"""
取出下一个Request并反序列化
:return: Request or None
"""
if self.db.llen(REDIS_KEY):
return loads(self.db.lpop(REDIS_KEY))
else:
return False
def clear(self):
self.db.delete(REDIS_KEY)
def empty(self):
return self.db.llen(REDIS_KEY) == 0
if __name__ == '__main__':
db = RedisQueue()
start_url = 'http://www.baidu.com'
weixin_request = WeixinRequest(url=start_url, callback='hello', need_proxy=True)
db.add(weixin_request)
request = db.pop()
print(request)
print(request.callback, request.need_proxy) - MySQL存储
import pymysql
from weixin.config import *
class MySQL():
def __init__(self, host=MYSQL_HOST, username=MYSQL_USER, password=MYSQL_PASSWORD, port=MYSQL_PORT,
database=MYSQL_DATABASE):
"""
MySQL初始化
:param host:
:param username:
:param password:
:param port:
:param database:
"""
try:
self.db = pymysql.connect(host, username, password, database, charset='utf8', port=port)
self.cursor = self.db.cursor()
except pymysql.MySQLError as e:
print(e.args)
def insert(self, table, data):
"""
插入数据
:param table:
:param data:
:return:
"""
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql_query = 'insert into %s (%s) values (%s)' % (table, keys, values)
try:
self.cursor.execute(sql_query, tuple(data.values()))
self.db.commit()
except pymysql.MySQLError as e:
print(e.args)
self.db.rollback() - 修改代理池
将测试代理的网址替换为目标爬取网址。筛选出可用代理 - 调度请求(主方法)
from requests import Session
from weixin.config import *
from weixin.db import RedisQueue
from weixin.mysql import MySQL
from weixin.request import WeixinRequest
from urllib.parse import urlencode
import requests
from pyquery import PyQuery as pq
from requests import ReadTimeout, ConnectionError
class Spider():
base_url = 'http://weixin.sogou.com/weixin'
keyword = 'NBA'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,ja;q=0.4,zh-TW;q=0.2,mt;q=0.2',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'IPLOC=CN1100; SUID=6FEDCF3C541C940A000000005968CF55; SUV=1500041046435211; ABTEST=0|1500041048|v1; SNUID=CEA85AE02A2F7E6EAFF9C1FE2ABEBE6F; weixinIndexVisited=1; JSESSIONID=aaar_m7LEIW-jg_gikPZv; ld=Wkllllllll2BzGMVlllllVOo8cUlllll5G@HbZllll9lllllRklll5@@@@@@@@@@; LSTMV=212%2C350; LCLKINT=4650; ppinf=5|1500042908|1501252508|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo1NDolRTUlQjQlOTQlRTUlQkElODYlRTYlODklOEQlRTQlQjglQTglRTklOUQlOTklRTglQTclODV8Y3J0OjEwOjE1MDAwNDI5MDh8cmVmbmljazo1NDolRTUlQjQlOTQlRTUlQkElODYlRTYlODklOEQlRTQlQjglQTglRTklOUQlOTklRTglQTclODV8dXNlcmlkOjQ0Om85dDJsdUJfZWVYOGRqSjRKN0xhNlBta0RJODRAd2VpeGluLnNvaHUuY29tfA; pprdig=ppyIobo4mP_ZElYXXmRTeo2q9iFgeoQ87PshihQfB2nvgsCz4FdOf-kirUuntLHKTQbgRuXdwQWT6qW-CY_ax5VDgDEdeZR7I2eIDprve43ou5ZvR0tDBlqrPNJvC0yGhQ2dZI3RqOQ3y1VialHsFnmTiHTv7TWxjliTSZJI_Bc; sgid=27-27790591-AVlo1pzPiad6EVQdGDbmwnvM; PHPSESSID=mkp3erf0uqe9ugjg8os7v1e957; SUIR=CEA85AE02A2F7E6EAFF9C1FE2ABEBE6F; sct=11; ppmdig=1500046378000000b7527c423df68abb627d67a0666fdcee; successCount=1|Fri, 14 Jul 2017 15:38:07 GMT',
'Host': 'weixin.sogou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
session = Session()
queue = RedisQueue()
mysql = MySQL()
def get_proxy(self):
"""
从代理池获取代理
:return:
"""
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
print('Get Proxy', response.text)
return response.text
return None
except requests.ConnectionError:
return None
def start(self):
"""
初始化工作
"""
# 全局更新Headers
self.session.headers.update(self.headers)
start_url = self.base_url + '?' + urlencode({'query': self.keyword, 'type': 2})
weixin_request = WeixinRequest(url=start_url, callback=self.parse_index, need_proxy=True)
# 调度第一个请求
self.queue.add(weixin_request)
def parse_index(self, response):
"""
解析索引页
:param response: 响应
:return: 新的响应
"""
doc = pq(response.text)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
url = item.attr('href')
weixin_request = WeixinRequest(url=url, callback=self.parse_detail)
yield weixin_request
next = doc('#sogou_next').attr('href')
if next:
url = self.base_url + str(next)
weixin_request = WeixinRequest(url=url, callback=self.parse_index, need_proxy=True)
yield weixin_request
def parse_detail(self, response):
"""
解析详情页
:param response: 响应
:return: 微信公众号文章
"""
doc = pq(response.text)
data = {
'title': doc('.rich_media_title').text(),
'content': doc('.rich_media_content').text(),
'date': doc('#post-date').text(),
'nickname': doc('#js_profile_qrcode > div > strong').text(),
'wechat': doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
}
yield data
def request(self, weixin_request):
"""
执行请求
:param weixin_request: 请求
:return: 响应
"""
try:
if weixin_request.need_proxy:
proxy = self.get_proxy()
if proxy:
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
return self.session.send(weixin_request.prepare(),
timeout=weixin_request.timeout, allow_redirects=False, proxies=proxies)
return self.session.send(weixin_request.prepare(), timeout=weixin_request.timeout, allow_redirects=False)
except (ConnectionError, ReadTimeout) as e:
print(e.args)
return False
def error(self, weixin_request):
"""
错误处理
:param weixin_request: 请求
:return:
"""
weixin_request.fail_time = weixin_request.fail_time + 1
print('Request Failed', weixin_request.fail_time, 'Times', weixin_request.url)
if weixin_request.fail_time < MAX_FAILED_TIME:
self.queue.add(weixin_request)
def schedule(self):
"""
调度请求
:return:
"""
while not self.queue.empty():
weixin_request = self.queue.pop()
callback = weixin_request.callback
print('Schedule', weixin_request.url)
response = self.request(weixin_request)
if response and response.status_code in VALID_STATUSES:
results = list(callback(response))
if results:
for result in results:
print('New Result', type(result))
if isinstance(result, WeixinRequest):
self.queue.add(result)
if isinstance(result, dict):
self.mysql.insert('articles', result)
else:
self.error(weixin_request)
else:
self.error(weixin_request)
def run(self):
"""
入口
:return:
"""
self.start()
self.schedule()
if __name__ == '__main__':
spider = Spider()
spider.run() - 运行
Ch 9 模拟登录
模拟登录并爬取GitHub
Cookie池的搭建
Ch 10 APP的爬取
Charles的使用
mitmproxy的使用
mitmdump爬取“得到”电子书信息
APPium的基本使用
APPium爬取微信朋友圈
APPium+mitmdump爬取京东商品
Ch 11 pyspider框架使用
pyspider框架应用场景较为单一,且可扩展程度不足,比较适合爬取固定分页展示内容的数据。
介绍
- pyspider是由国人binux编写的强大的网络爬虫系统,其GitHub地址为https://github.com/binux/pyspider,官方文档地址为http://docs.pyspider.org/。
- pyspider带有强大的 WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,它支持多种数据库后端、多种消息队列、JavaScript渲染页面的爬取,使用起来非常方便。
- pyspider开发快速便捷,适合中小型项目。
基本功能
- 提供方便易用的WebUI系统,可视化地编写和调试爬虫。
- 提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
- 支持多种后端数据库,如MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
- 支持多种消息队列,如RabbitMQ、Beanstalk、Redis、Kombu。
- 提供优先级控制、失败重试、定时抓取等功能。
- 对接了PhantomJS,可以抓取JavaScript渲染的页面。
- 支持单机和分布式部署,支持Docker部署。
与Scrapy比较
- pyspider提供了WebUI,爬虫的编写、调试都是在WebUI中进行的。而Scrapy原生是不具备这个功能的,它采用的是代码和命令行操作,但可以通过对接Portia实现可视化配置。
- pyspider调试非常方便,WebUI操作便捷直观。Scrapy则是使用parse命令进行调试,不够方便。
- pyspider支持PhantomJS来进行JavaScript谊染页面的采集。Scrapy可以对接Scrapy-Splash组件,这需要额外配置。
- pyspider中内置了pyquery作为选择器。Scrapy对接了XPath、css选择器和正则匹配。
- pyspider的可扩展程度不足,可配制化程度不高。Scrapy可以通过对接Middleware、Pipeline、Extension等组件实现非常强大的功能,模块之间的耦合程度低,可扩展程度极高。
pyspider架构
pyspider的架构主要分为Scheduler(调度器)、Fetcher( 抓取器)、Processer(处理器)三个部分,整个爬取过程受到Monitor(监控器)的监控,抓取的结果被Result Worker(结果处理器)处理,如图:
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processer负责解析网页内容,然后将新生成的Request发给Scheduler进行调度,将生成的提取结果输出保存。
执行过程如下:
- 每个pyspider的项目对应一个Python脚本,该脚本中定义了一个Handler类,它有一个on_start()方法。爬取首先调用on_start()方法生成最初的抓取任务,然后发送给Scheduler进行调度。
- Scheduler将抓取任务分发给Fetcher进行抓取,Fetcher执行并得到响应,随后将响应发送给Processer。
- Processer处理响应并提取出新的URL生成新的抓取任务,然后通过消息队列的方式通知Schduler当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler。如果生成了新的提取结果,则将其发送到结果队列等待Result Worker处理。
- Scheduler接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回Fetcher进行抓取。
- 不断重复以上工作,直到所有的任务都执行完毕,抓取结束。
- 抓取结束后,程序会回调on_finished()方法,这里可以定义后处理过程。
基本使用
相关链接
- 官方文档:http://docs.pyspider.org/
- PyPI:https://pypi.python.org/pypi/pyspider
- GitHub:https://github.com/binux/pyspider
- 官方教程:http://docs.pyspider.org/en/latest/tutorial
- 在线实例:http://demo.pyspider.org
安装
pip3 install pyspider- PhantomJS安装:phantomjs-2.1.1-windows.zip,解压后将bin路径配置到用户Path中
- 常见错误及解决:
https://www.cnblogs.com/Mayfly-nymph/p/10808088.html
https://github.com/binux/pyspider/issues/898
https://www.cnblogs.com/shaosks/p/6856086.html - 启动:
pyspider [all]
源码
from pyspider.libs.base_handler import * |
新建项目
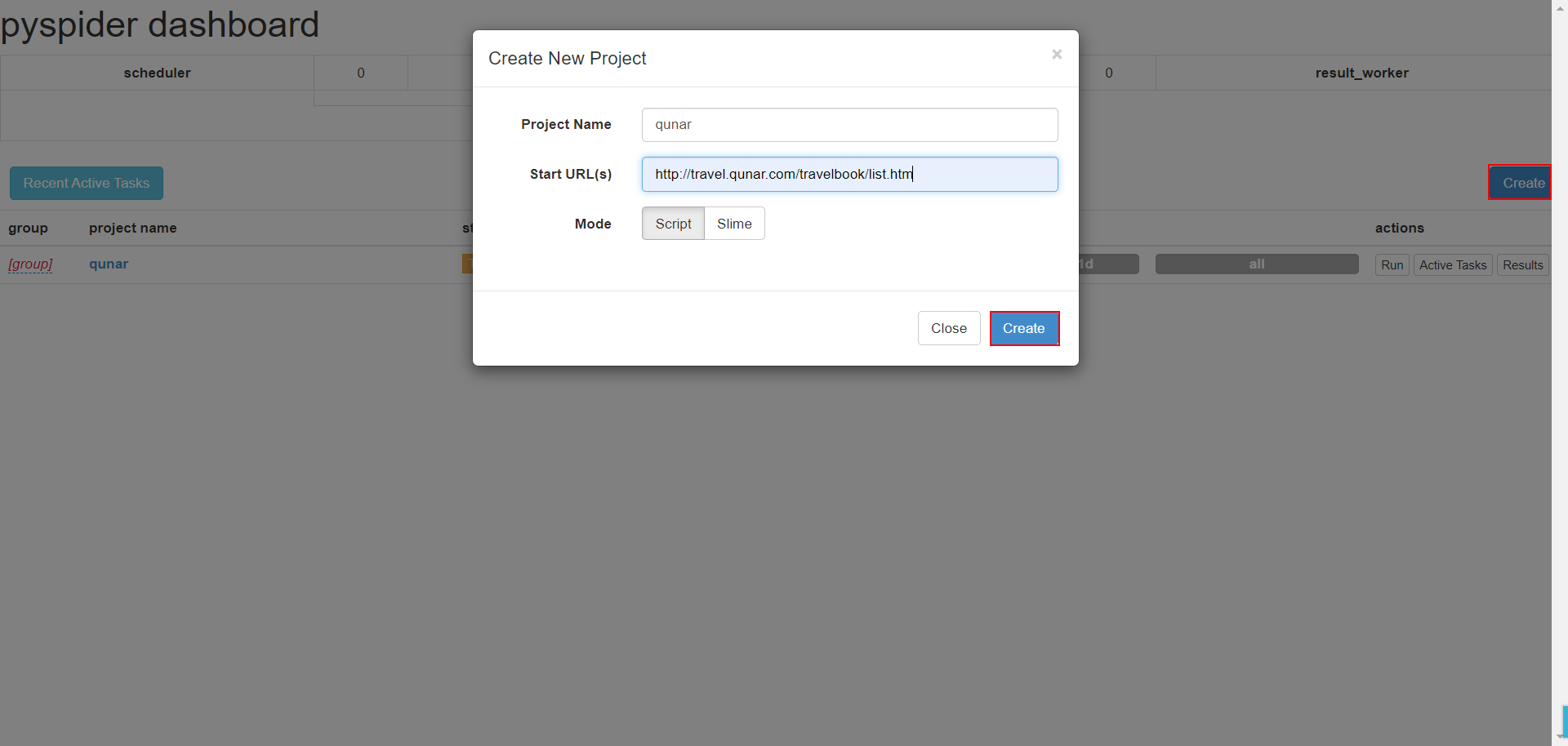
爬取首页
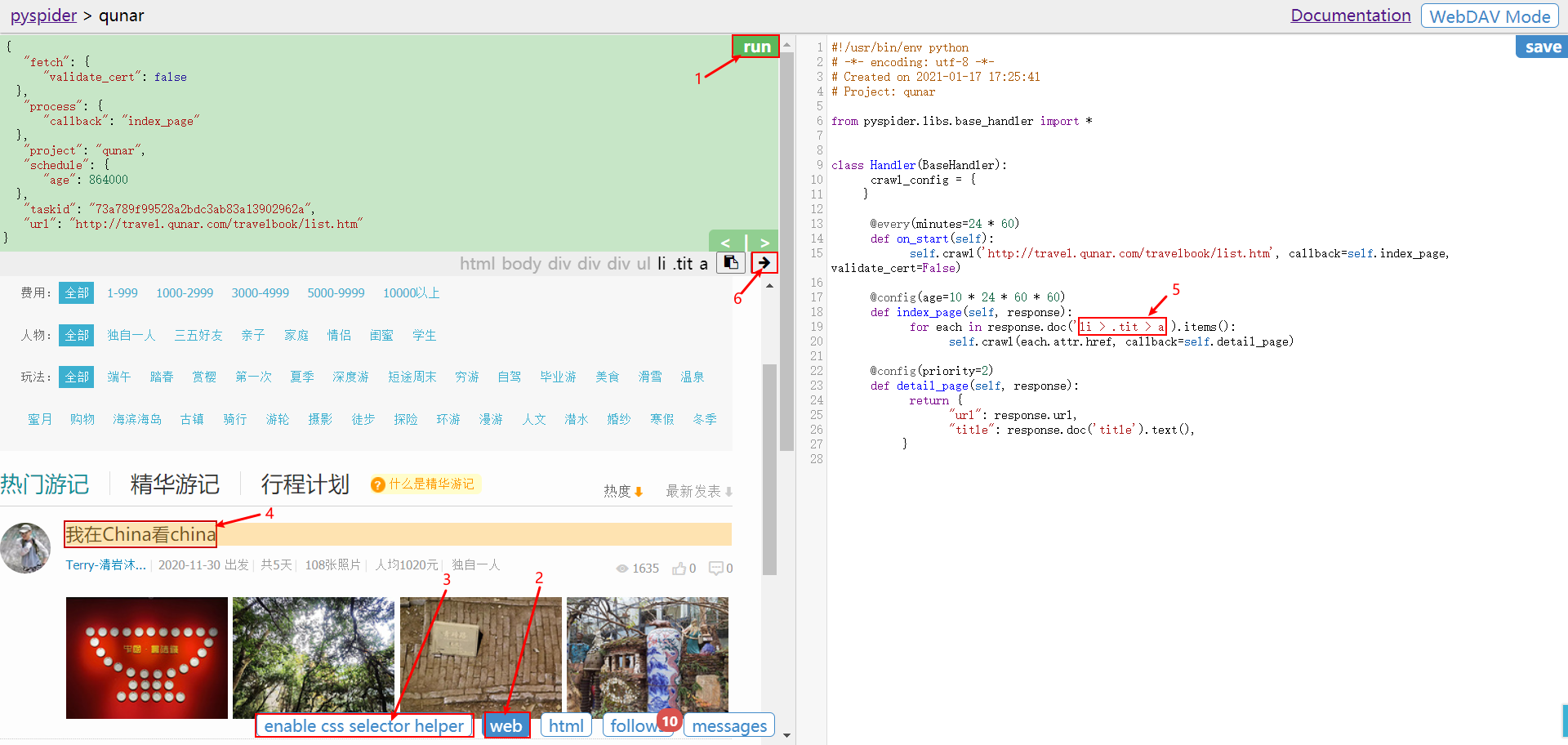
爬取详情页
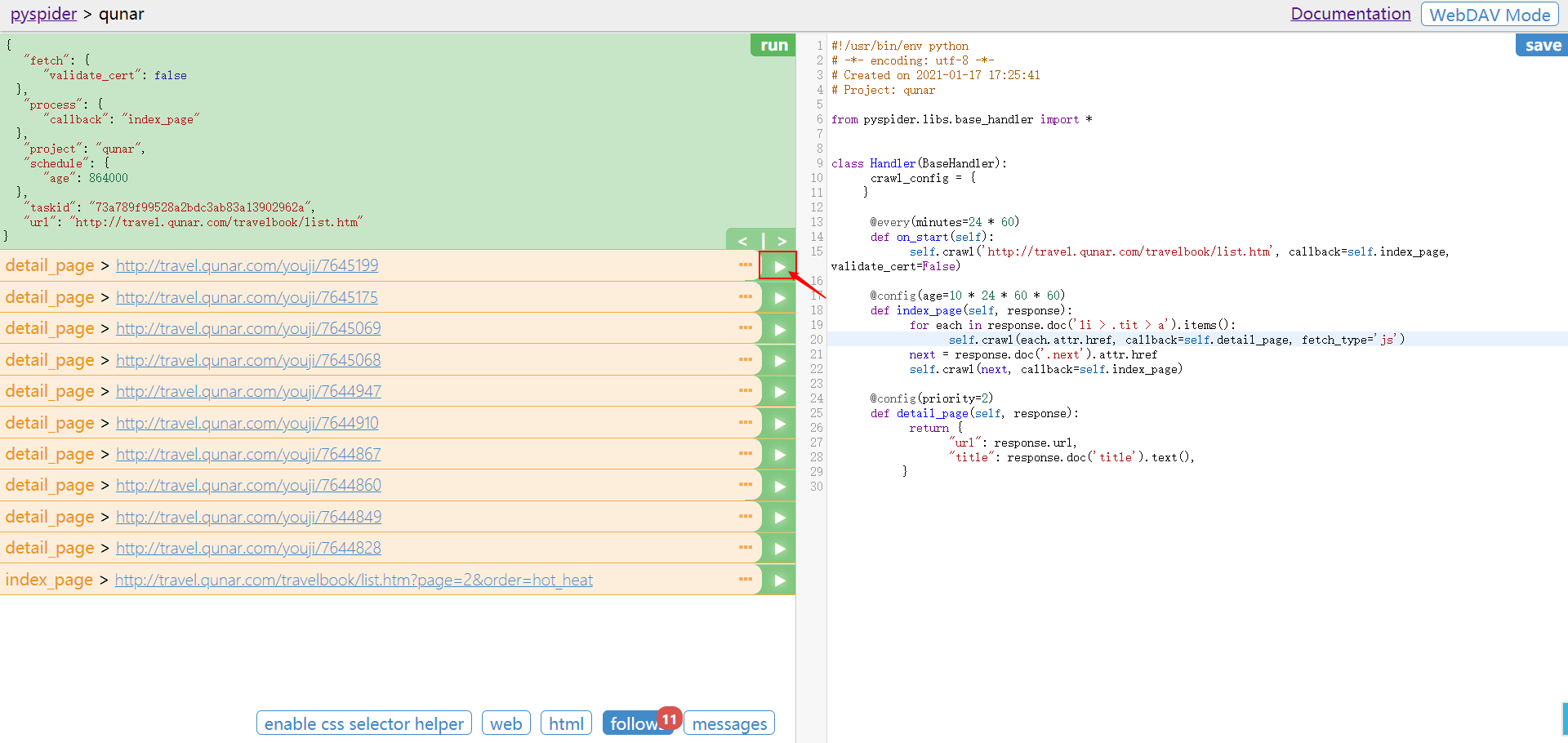
爬取的页面无法显示图片,出现此现象的原因是pyspider默认发送HTTP请求,请求的HTML文档本身就不包含img节点。但是在浏览器中我们看到了图片,这是因为这张图片是后期经过JavaScript出现的。
pyspider内部对接了PhantomJS,将index_page()中生成抓取详情页的请求方法添加一个参数 fetch_type='js'即可
启动爬虫
- 在最左侧可以定义项目的分组,以便管理。
- rate/burst代表当前的爬取速率,rate代表每秒发出多少个请求,burst(并发数)相当于流量控制中的令牌桶算法的令牌数,rate和burst设置的越大,爬取速率越快。
- process中的5m、1h、1d指的是最近5分、l小时、l天内的请求情况,all代表所有的请求情况。请求由不同颜色表示,蓝色的代表等待被执行的请求,绿色的代表成功的请求,黄色的代表请求失败后等待重试的请求,红色的代表失败次数过多被忽略的请求,这样可以直观知道爬取的进度和请求情况。
- 点击Active Tasks,可查看最近请求的详细状况。
- 点击Results,查看所有爬取结果。
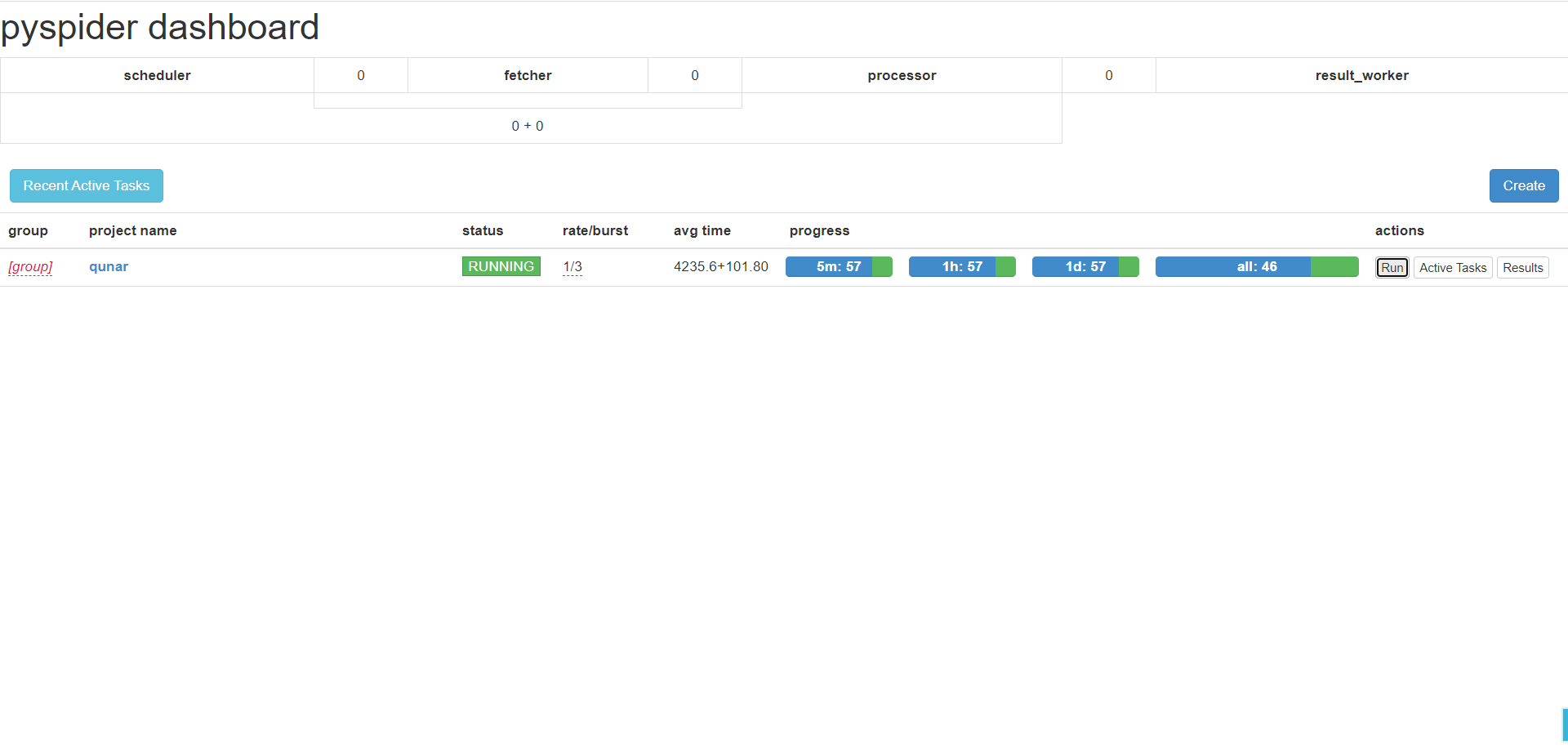
详解
参见官方文档:http://docs.pyspider.org/
命令行
http://docs.pyspider.org/en/latest/Command-Line/
crawl()方法
http://docs.pyspider.org/en/latest/apis/self.crawl/
任务区分
在pyspider中判断两个任务是否是重复的,使用的是该任务对应的URL的MD5值作为任务的唯一ID,如果ID相同,那么两个任务就会判定为相同,其中一个就不会爬取。这时可以重写task_id()方法,改变这个ID的计算方式来实现不同任务的区分,如下所示:
import json |
全局配置
pyspider可以使用crawl_config来指定全局的配置,配置中的参数会和crawl()方法创建任务时的参数合井。
如要全局配置一个Headers,可以定义如下代码:
class Handler(BaseHandler): |
定时爬取
通过every属性来设置爬取的时间间隔:
在有效时间内爬取不会重复。所以要把有效时间设置得比重复时间更短,即age的时间小于minutes的时间这样才可以实现定时爬取。
#minutes为爬取的时间间隔,单位为分钟 |
项目状态
- TODO:它是项目刚刚被创建还未实现时的状态。
- STOP:如果想停止某项目的抓取,可以将项目的状态设置为STOP 。
- CHECKING:正在运行的项目被修改后就会变成CHECKING状态,项目在中途出错需要调整的时候会遇到这种情况。
- DEBUG/RUNNING:这两个状态对项目的运行没有影响,状态设置为任意一个,项目都可以运行,但是可以用二者来区分项目是否已经测试通过。
- PAUSE:当爬取过程中出现连续多次错误时,项目会自动设置为PAUSE状态,并等待一定时间后继续爬取。
删除项目
pyspider中没有直接删除项目的选项。如要删除任务,那么将项目的状态设置为STOP,将分组的名称设置为delete,等待24小时,则项目会自动删除。
Ch 12 Scrapy框架使用
Scrapy框架介绍
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。
架构介绍
- Scrapy框架的架构,如图。
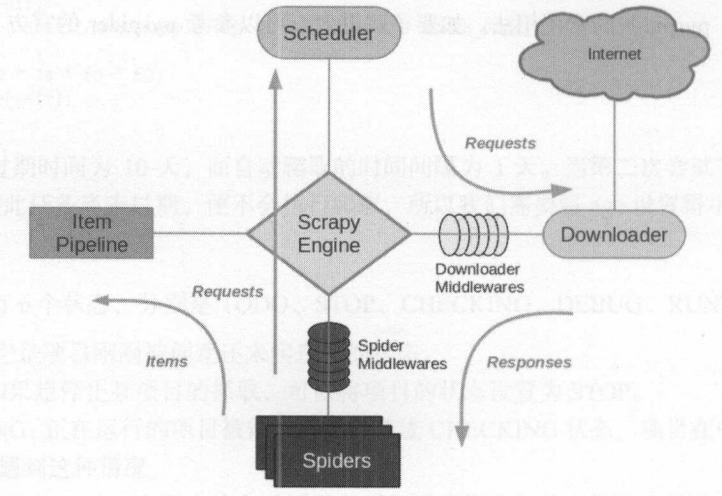
- 分为如下的几个部分。
- Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Item。项目,定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
- Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
- Downloader。下载器,下载网页内容,并将网页内容返回给Spiders。
- Spiders。爬虫,定义了爬取的逻辑和网页的解析规则,主要负责解析响应并生成提取结果和新的请求。
- Item Pipeline。项目管道,负责处理由爬虫从网页中抽取的项目,主要任务是清洗、验证和存储数据。
- Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应 。
- Spider Middlewares。爬虫中间件,位于引擎和爬虫之间的钩子框架,主要处理爬虫输入的响应和输出的结果及新的请求 。
数据流
- Scrapy中的数据流由引擎控制,数据流的过程如下。
- Engine首先打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL。
- Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request的形式调度。
- Engine向Scheduler请求下一个要爬取的URL。
- Scheduler返回下一个要爬取的URL给Engine,Engine将URL通过Downloader MiddJewares转发给Downloader下载。
- 一旦页面下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine。
- Engine从下载器中接收到Response,并将其通过Spider Middlewares发送给Spider处理。
- Spider处理Response,并返回爬取到的Item及新的Request给Engine。
- Engine将Spider返回的Item给Item Pipeline,将新的Request给Scheduler。
- 重复第2步到第8步,直到Scheduler中没有更多的Request, Engine关闭该网站,爬取结束。通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持,Scrapy最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
项目结构
项目文件基本结构如下所示:
scrapy.cfg |
- 各个文件的功能描述如下。
- scrapy.cfg :Scrapy项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:定义了Item数据结构,所有的Item的定义都可以放这里。
- pipelines.py:定义了Item Pipeline的实现,所有的Item Pipeline的实现都可以放这里。
- settings.py:定义了项目的全局配置。
- middlewares.py:它定义Spider Middlewares和Downloader Middlewares的实现。
- spiders:其内包含一个个Spider的实现,每个Spider都有一个文件。
Scrapy入门
准备工作
安装:pip install scrapy
官方文档:https://docs.scrapy.org/en/latest/intro/tutorial.html
中文文档:https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html
创建项目
scrapy startproject tutorial
在本目录创建一个名为tutorial的项目文件夹。文件夹结构如下所示:
scrapy.cfg # Scrapy部署时的配置文件 |
创建Spider
Spider是自己定义的类,用来从网页里抓取内容,并解析抓取的结果。这个类必须继承Scrapy提供的Spider类scrapy.Spider,还要定义Spider的名称和起始请求,以及怎样处理爬取后的结果的方法。
使用命令行创建一个Spider:
cd tutorial |
执行完毕之后,spiders文件夹中多了一个quotes.py,就是刚刚创建的Spider,内容如下所示:
import scrapy |
创建Item
Item是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。观察目标网站,我们可以获取到到内容有text、author、tags。
定义Item,此时将items.py修改如下:
import scrapy |
解析Response
Spider内的parse()方法的参数resposne是start_urls里面的链接爬取后的结果。所以在parse())方法中,我们可以直接对response变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都要进行处理。提取的方式可以是css选择器或XPath选择器。这里使用css选择器进行选择,parse()方法的改写如下所示:
def parse(self, response): |
使用Item
Item可以理解为一个字典,在声明的时候需要实例化,然后依次用刚才解析的结果赋值Item的每一个字段,最后将Item返回。
def parse(self, response): |
后续Request
import scrapy |
- callback:回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或生成下一个请求,回调函数如上文的parse()所示。
- urljoin():可以将相对URL构造成一个绝对的URL。例如,获取到的下一页地址是/page/2, urljoin()方法处理后得到的结果就是:http://quotes.toscrape.com/page/2/。
- 最后一行代码通过url和callback变量构造了一个新的请求,回调函数callback依然使用parse()方法。这个请求完成后,响应会重新经过parse方法处理,得到第二页的解析结果,然后生成第二页的下一页,也就是第三页的请求。这样爬虫就进入了一个循环,直到最后一页。
运行
scrapy crawl quotes
保存到文件
将爬取的结果保存成JSON文件,可以执行如下命令:scrapy crawl quotes -o quotes.json
命令运行后,项目内多了一个quotes.json文件,文件包含了刚才抓取的所有内容。
另外还可以每一个Item输出一行JSON,输出后缀为jl,为jsonline的缩写,命令如下所示:scrapy crawl quotes -o quotes.jl
或scrapy crawl quotes -o quotes.jsonlines
输出格式支持多种,例如csv、xml、pickle、marshal等,还支持ftp、s3等远程输出,另外还可以通过自定义ItemExporter来实现其他的输出。
例如,下面命令对应的输出分别为csv、xml、pickle、marshal格式以及ftp远程输出:
scrapy crawl quotes -o quotes.csv |
其中,ftp输出需要正确配置用户名、密码、地址、输出路径,否则会报错。
通过Scrapy提供的Feed Export,可以轻松地输出抓取结果到文件。对于一些小型项目来说,这应该足够了。不过如果想要更复杂的输出,如输出到数据库等,我们可以使用Item Pileline来完成。
使用Item Pipeline
进行更复杂的操作,如将结果保存到MongoDB数据库,或者筛选某些有用的Item,则可以定义Item Pileline来实现。
Item Pipeline为项目管道。当Item生成后,它会自动被送到Item Pipeline进行处理,常用Item Pipeline来做如下操作:
- 清理 HTML 数据 。
- 验证爬取数据,检查爬取字段。
- 查重井丢弃重复内容 。
- 将爬取结果保存到数据库 。
要实现Item Pipeline,只需要定义一个类并实现process_item()方法即可。启用Item Pipeline后,Item Pipeline会自动调用这个方法。process_item()方法必须返回包含数据的字典或Item对象,或者抛出DropItem异常 。
process_item()方法有两个参数。一个参数是item,每次Spider生成的Item都会作为参数传递过来。另一个参数是spider,就是Spider的实例。
如下实现一个Item Pipeline,筛掉text长度大于50的Item,并将结果保存到MongoDB。修改项目里的pipelines.py文件,内容如下所示:
import pymongo
from scrapy.exceptions import DropItem
class TextPipeline(object):
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][0:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text')
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()MongoPipeline类实现了API定义的另外几个方法。
- from_crawler()。是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数就是crawler,通过crawler我们可以拿到全局配置的每个配置信息。在全局配置settings.py中,可以定义MONGO_URI和MONGO_DB来指定MongoDB连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取settings.py中的配置的。
- open_spider()。当Spider开启时,这个方法被调用。上文程序中主要进行了一些初始化操作。
- close_spider()。当Spider关闭时,这个方法会调用。上文程序中将数据库连接关闭。
- process_item()方法则执行了数据插入操作 。
settings.py中加入如下内容:
ITEM_PIPELINES = {
'tutorial.pipelines.TextPipeline': 300,
'tutorial.pipelines.MongoPipeline': 400,
}
MONGO_URI='localhost'
MONGO_DB='tutorial'赋值ITEM_PIPELINES字典,键名是Pipeline的类名称,键值是调用优先级,是一个数字,数字越小则对应的Pipeline越先被调用。爬取结束后, MongoDB中创建了一个tutorial的数据库、Quoteltem的表。
Selector用法
Selector是基于lxml来构建的,支持XPath选择器、css选择器以及正则表达式,功能全面,解析速度和准确度非常高。
直接使用
Selector是一个可以独立使用的模块。可以直接利用Selector这个类来构建一个选择器对象,然后调用它的相关方法如xpath()、css()等来提取数据。
例如,针对一段HTML代码,可以用如下方式构建Selector对象来提取数据:
from scrapy import Selector |
Scrapy shell
这里借助Scrapy shell来模拟Scrapy请求的过程,讲解相关的提取方法。
用官方文档的一个样例页面来做演示:https://docs.scrapy.org/en/latest/topics/selectors.html。
开启Scrapy shell,在命令行输入如下命令:scrapy shell https://docs.scrapy.org/en/latest/topics/selectors.html
就进入到Scrapy shell模式。这个过程是Scrapy发起了一次请求,请求的URL就是刚才命令行下输入的URL,然后把一些可操作的变量传递给我们,如request、response等,如图。
我们可以在命令行模式下输入命令调用对象的一些操作方法,回车之后实时显示结果。这与Python的命令行交互模式是类似的。
XPath选择器
response有一个属性selector,调用response.selector返回的内容就相当于用response的body构造了一个Selector对象。通过这个Selector对象我们可以调用解析方法如xpath()、css()等,通过向方法传入XPath或css选择器参数就可以实现信息的提取。
实例:
# 返回类型是Selector组成的列表,即Selectorlist类型, |
CSS选择器
用法类似XPath选择器,实例如下:
response.css('a[href="img1.html"]::text').extract_first() # 获取文本 |
正则匹配
实例:
# 返回匹配的分组列表 |
Spider用法
Spider运行流程
- Spider要做的事就是如下两件:
- 定义爬取网站的动作。
- 分析爬取下来的网页。
- 对于Spider类来说,整个爬取循环过程如下所述。
- 以初始的URL初始化Request,并设置回调函数。当该Request成功请求并返回时,Response生成井作为参数传给该回调函数。
- 在回调函数内分析返回的网页内容。返回结果有两种形式,一种是解析到的有效结果返回字典或Item对象,它们可以经过处理后(或直接)保存。另一种是解析得到下一个(如下一页)链接,可以利用此链接构造Request并设置新的回调函数,返回Request等待后续调度。
- 如果返回的是字典或Item对象,可通过Feed Exports等组件将退回结果存入到文件。如果设置了Pipeline的话,可以使用Pipeline处理(如过滤、修正等)并保存。
- 如果返回的是Reqeust,那么Request执行成功得到Response之后,Response会被传递给Request中定义的回调函数,在回调函数中我们可以再次使用选择器来分析新得到的网页内容,并根据分析的数据生成Item。
通过以上几步循环往复进行,即可完成站点的爬取。
Spider类分析
scrapy.spiders.Spider这个类提供了start requests()方法的默认实现,读取并请求start_urls属性,并根据返回的结果调用parse()方法解析结果。
- Scrapy有如下一些基础属性。
- name。爬虫名称,是定义Spider名字的字符串。Spider的名字定义了Scrapy如何定位并初始化Spider,必须是唯一的。不过可以生成多个相同的Spider实例,数量没有限制。
- allowed_domains。允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。
- start_urls。起始URL列表,当没有实现start_requests()方法时,默认会从这个列表开始抓取。
- custom_settings。一个字典,是专属于本Spider的配置,此设置会覆盖项目全局的设置,必须在初始化前被更新,并定义成类变量。
- crawler。由from_crawler()方法设置,代表的是本Spider类对应的Crawler对象。Crawler对象包含了很多项目组件,利用它可以获取项目的一些配置信息,如最常见的获取项目的设置信息,即Settings。
- settings。是一个Settings对象,利用它可以直接获取项目的全局设置变量。
- 除了基础属性,Spider还有一些常用的方法。
- start_requests()。此方法用于生成初始请求,必须返回一个可迭代对象。此方法会默认使用start_urls里面的URL来构造Request,而且Request是GET请求方式。如果想在启动时以POST方式访问某个站点,可以直接重写这个方法,发送POST请求时使用FormRequest即可。
- parse()。当Response没有指定回调函数时,该方法会默认被调用。它负责处理Response,处理返回结果,并从中提取想要的数据和下一步的请求,然后返回。该方法需要返回一个包含Request或Item的可迭代对象。
- closed()。当Spider关闭时,该方法会被调用,在这里-般会定义释放资源的一些操作或其他收尾操作。
Downloader Middleware用法
Downloader Middleware即下载中间件,是处于Scrapy的Request和Response之间的处理模块。用于实现修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等功能。
- 在整个架构���起作用的位置是以下两个。
- 在Scheduler调度出队列的Request发送给Doanloader下载之前,也就是在Request执行下载之前对其进行修改。
- 在下载后生成的Response发送给Spider之前,在生成Resposne被Spider解析之前对其进行修改。
使用说明
Scrapy已经提供了许多Downloader Middleware,如负责失败重试、向动重定向等功能的Middleware,它们被DOWNLOADER_MIDDLEWARES_BASE变量所定义。
DOWNLOADER_MIDDLEWARES_BASE变量的内容如下所示:
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, |
这是一个字典格式,字典的键名是Scrapy内置的Downloader Middleware的名称,键值代表了调用的优先级,优先级是一个数字,数字越小代表越靠近 Scrapy引擎,数字越大代表越靠近Downloader,数字小的Downloader Middleware会被优先调用。
如果自己定义的Downloader Middleware要添加到项目里,DOWNLOADER_MIDDLEWARES_BASE变量不能直接修改。Scrapy提供了另外一个设置变量DOWNLOADER_MIDDLEWARES,直接修改这个变量就可以添加自己定义的Downloader Middleware,以及禁用DOWNLOADER_MIDDLEWARES_BASE里面定义的Downloader Middleware。
核心方法
每个Downloader Middleware都定义了一个或多个方法的类,核心的方法有如下三个,我们只需要实现至少一个方法,就可以定义一个Downloader Middleware。
- process_request(request, spider)
Request被Scrapy引擎调度给Downloader之前,process_request()方法就会被调用,也就是在Request从队列里调度出来到Downloader下载执行之前,都可以用process_request()方法对Request进行处理。方法的返回值必须为None、Response对象、Request对象之一 ,或者抛出IgnoreRequest异常 。- process_request()方法的参数有如下两个。
- request,Request对象,即被处理的Request。
- spider,Spdier对象,即此Request对应的Spider。
- 返回类型不同,产生的效果也不同。如下。
- 当返回是None时,Scrapy将继续处理该Request,接着执行其他Downloader Middleware的process_request()方法,一直到Downloader把 Request执行后得到Response才结束。这个过程其实就是修改Request的过程,不同的Downloader Middleware按照设置的优先级顺序依次对 Request进行修改,最后送至Downloader执行。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_request()和process_exception()方法就不会被继续调用,每个 Downloader Middleware的process_response()方法转而被依次调用。调用完毕之后,直接将Response对象发送给Spider来处理。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_request()方法会停止执行。这个Request会重新放到调度队列里,其实它就是一个全新的Request,等待被调度。如果被Scheduler调度了,那么所有的Downloader Middleware的process request()方法会被重新按照顺序执行。
- 如果IgnoreRequest异常抛出,则所有的Downloader Middleware的process_exception()方法会依次执行。如果没有一个方法处理这个异常,那么Request的errorback()方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
- process_request()方法的参数有如下两个。
- process_response(request, response, spider)
Downloader执行Request下载之后,会得到对应的Response。Scrapy引擎便会将Response发送给Spider进行解析。在发送之前,都可以用process_response()方法来对Response进行处理。方法的返回值必须为Request对象、Response对象之一,或者抛出IgnoreRequest异常。- process_response()方法的参数有如下三个。
- request,Request对象,即此Response对应的Request。
- response,Response对象,即此被处理的Response 。
- spider,Spider对象,即此Response对应的Spider。
- 下面为不同的返回情况。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_response()方法不会继续调用。该Request对象会重新放到调度队列里等待被调度,它相当于一个全新的Request。然后,该Request会被process_request()方法顺次处理。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_response()方法会继续调用,继续对该Response对象进行处理。
- 如果IgnoreRequest异常抛出,则Request的errorback()方法会回调。如果该异常还没有被处理,那么它便会被忽略。
- process_response()方法的参数有如下三个。
- process_exception(request, exception, spider)
当Downloader或process_request()方法抛出异常时,例如抛出IgnoreRequest异常,process_exception()方法就会被调用。方法的返回值必须为 None、Response对象、Request对象之一。- process_exception()方法的参数有如下三个。
- request,Request对象,即产生异常的Request。
- exception,Exception对象,即抛出的异常。
- spdier,Spider 对象,即Request对应的Spider。
- 下面为不同的返回值。
- 当返回为None时,更低优先级的Downloader Middleware的process_exception()会被继续顺次调用,直到所有的方法都被调度完毕。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_exception()方法不再被继续调用,每个Downloader Middleware的process_response()方法转而被依次调用。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_exception()也不再被继续调用,该Request对象会重新放到调度队列里面等待被调度,它相当于一个全新的Request。然后,该Request又会被process_request()方法顺次次处理。
- process_exception()方法的参数有如下三个。
项目实战
项目地址:https://github.com/Python3WebSpider/ScrapyDownloaderTest
新建项目:
scrapy startproject scrapydownloadertest新建spider:
scrapy genspider httpbin httpbin.org修改Spider内容如下:
# -*- coding: utf-8 -*-
# httpbin.py
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
self.logger.debug(response.text)
self.logger.debug('Status Code: ' + str(response.status))修改请求的User-Agent有两种方式:
- 修改settings里的USER_AGENT变量,一般用此方法,如下添加一行USER_AGENT定义:
# settings.py
USER_AGENT = ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36') - 借助Donwload Middleware,在middlewares.py文件添加一个自定义的RandomUserAgentMiddleware类,并在settings.py文件中添加
# settings.py
DOWNLOADER_MIDDLEWARES = {
'scrapydownloadertest.middlewares.RandomUserAgentMiddleware': 543,
}# middlewares.py
import random
from scrapy import Request
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = [
'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)
def process_response(self, request, response, spider):
response.status = 201
return response
- 修改settings里的USER_AGENT变量,一般用此方法,如下添加一行USER_AGENT定义:
执行
scrapy crawl httpbin获取Scrapy发送的Request信息如下,成功修改User-Agent并返回201状态码:[httpbin] DEBUG: Status Code: 201
{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"X-Amzn-Trace-Id": "Root=1-60190098-419bb41a68b4c46b3f2eb440"
},
"origin": "60.33.123.25",
"url": "http://httpbin.org/get"
}
Spider Middleware用法
Spider Middleware有如下三个作用。
- 在Downloader生成的Response发送给Spider之前对Response进行处理。
- 在Spider生成的Request发送给Scheduler之前对Request进行处理。
- 在Spider生成的Item发送给Item Pipeline之前对Item进行处理。
使用说明
Scrapy已经提供了许多Spider Middleware,它们被SPIDER_MIDDLEWARES_BASE这个变盘所定义。
SPIDER_MIDDLEWARES_BASE变量的内容如下:
{ |
和Downloader Middleware一样,Spider Middleware首先加入到SPIDER_MIDDLEWARES设置中,该设置会和Scrapy中SPIDER_MIDDLEWARES_BASE定义的Spider Middleware合并。然后根据键值的数字优先级排序,得到一个有序列表。第一个Middleware是���靠近引擎的,最后一个Middleware是最靠近 Spider的。
核心方法
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有如下4个,只需要实现其中一个方法就可以定义一个Spider Middleware。下面是这4个方法的详细用法。
- process_spider_input(response, spider)
当Response被Spider Middleware处理时,process_spider_input()方法被调用。- process_spider_input()方法的参数有如下两个。
- response,Response对象,即被处理的Response。
- spider,Spider对象,即该Response对应的Spider。
- process_spider_input()应该返回None或者抛出一个异常。
- 如果它返回None,Scrapy将会继续处理该Response,调用所有其他的Spider Middleware,直到Spider处理该Response。
- 如果它抛出一个异常,Scrapy将不会调用任何其他Spider Middleware的process_spider_input()方法,而调用Request的errback()方法。errback()的输出将会被重新输入到中间件中,使用process_spider_output()方法来处理,当其抛出异常时则调用 process_spider_exception()来处理。
- process_spider_input()方法的参数有如下两个。
- process_spider_output(response, result, spider)
当Spider处理Response返回结果时,process_spider_output()方法被调用。- process_spider_output()方法的参数有如下三个。
- response,Response对象,即生成该输出的Response。
- result,包含Request或Item对象的可迭代对象,即Spider返回的结果。
- spider,Spider对象,即其结果对应的Spider。
- process_spider_output()必须返回包含Request或Item对象的可迭代对象。
- process_spider_output()方法的参数有如下三个。
- process_spider_exception(response, exception, spider)
当Spider或Spider Middleware的process_spider_input()方法抛出异常时,process_spider_exception()方法被调用。- process_spider_exception()方法的参数有如下三个。
- response,Response对象,即异常被抛出时被处理的Response。
- exception,Exception对象,即被抛出的异常。
- spider,Spider对象,即抛出该异常的Spider。
- process_spider_exception()必须要么返回None,要么返回一个包含Response或Item对象的可迭代对象。
- 如果返回None,Scrapy将继续处理该异常,调用其他Spider Middleware中的process_spider_exception()方法,直到所有Spider Middleware都被调用。
- 如果返回一个可迭代对象,则其他Spider Middleware的process_spider_output()方法被调用,其他的process_spider_exception()不会被调用。
- process_spider_exception()方法的参数有如下三个。
- process_start_requests(start_requests, spider)
process_start_requests()方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output(),只不过没有相关联的 Response,并且必须返回Request。- process_start_requests()方法的参数有如下两个。
- start_requests,包含Request的可迭代对象,即Start Requests。
- spider, Spider对象,即Start Requests所属的Spider。
- process_start_requests()必须返回另一个包含Request对象的可迭代对象。
- process_start_requests()方法的参数有如下两个。
Item Pipeline用法
- Item Pipeline的调用发生在Spider产生Item之后。当Spider解析完Response之后,Item就会传递到Item Pipeline,被定义的Item Pipeline组件会顺次调用,完成一连串的处理过程,比如数据清洗、存储等。
- Item Pipeline的主要功能有如下。
- 清理HTML数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果保存到数据库。
核心方法
- process_item(item, spider)
process_item()是必须要实现的方法,被定义的Item Pipeline会默认调用这个方法对Item进行处理。比如进行数据处理或者将数据写入到数据库等操作。必须返回Item类型的值或者抛出一个Drop Item异常。- process_item()方法的参数有如下两个。
- item,Item对象,即被处理的Item 。
- spider,Spider对象,即生成该Item的Spider。
- process_item()方法的返回类型归纳如下。
- 如果返回的是Item对象,那么此Item会被低优先级的Item Pipeline的process_item()方法处理,直到所有的方法被调用完毕。
- 如果它抛出的是Drop Item异常,那么此Item会被丢弃,不再进行处理。
- process_item()方法的参数有如下两个。
- open_spider(self, spider)
open_spider()方法是在Spider开启的时候被自动调用的。在这里可以做一些初始化操作,如开启数据库连接等。其中,参数spider就是被开启的 Spider对象。 - close_spider(spider)
close_spider()方法是在Spider关闭的时候自动调用的。在这里可以做一些收尾工作,如关闭数据库连接等。其中,参数spider就是被关闭的Spider对象。 - from_crawler(cls, crawler)
from_crawler()方法是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数是crawler,通过crawler对象,可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例。
项目示例
新建项目:scrapy startproject images360
新建一个Spider:scrapy genspider images images.so.com
构造请求
打开浏览器开发者模式,过滤器切换到XHR选项,分析Ajax请求。其中两个请求如下:https://image.so.com/zjl?ch=beauty&sn=30&listtype=new&temp=1
https://image.so.com/zjl?ch=beauty&sn=60&listtype=new&temp=1可知,sn为偏移值,sn为30,返回前30张图片;sn为60,返回第31-60张图片。
# -*- coding: utf-8 -*-
# images.py
import json
from scrapy import Spider, Request
from urllib.parse import urlencode
from images360.items import ImageItem
class ImagesSpider(Spider):
name = 'images'
allowed_domains = ['images.so.com']
start_urls = ['http://images.so.com/']
def start_requests(self):
data = {'ch': 'beauty', 'listtype': 'new'}
base_url = 'https://image.so.com/zjl?'
for page in range(1, self.settings.get('MAX_PAGE') + 1):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
yield Request(url, self.parse)
def parse(self, response):
result = json.loads(response.text)
for image in result.get('list'):
item = ImageItem()
item['id'] = image.get('id')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('title')
item['thumb'] = image.get('qhimg_thumb')
yield item提取信息
定义Item:# items.py
from scrapy import Item, Field
class ImageItem(Item):
collection = table = 'images' #分别代表MongoDB和MySQL存储名称
id = Field()
url = Field()
title = Field()
thumb = Field()存储信息
需要提前建数据库和建表。# pipelines.py
import pymongo
import pymysql
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.collection
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(host=self.host, user=self.user, password=self.password, db=self.database, charset='utf8',
port=self.port)
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
print(item['title'])
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
class ImagePipeline(ImagesPipeline):
'''
负责下载图片
file_path():返回保存的文件名
item_completed():处理下载成功和失败的情况
get_media_requests():将Item对象的url字段取出生成Request对象,加入调度队列
'''
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])运行
修改settings.py:BOT_NAME = 'images360'
SPIDER_MODULES = ['images360.spiders']
NEWSPIDER_MODULE = 'images360.spiders'
ROBOTSTXT_OBEY = False
# 注意调用顺序
ITEM_PIPELINES = {
'images360.pipelines.ImagePipeline': 300,
'images360.pipelines.MysqlPipeline': 302,
'images360.pipelines.MongoPipeline': 302,
}
IMAGES_STORE = './images'
MAX_PAGE = 50
MONGO_URI = 'localhost'
MONGO_DB = 'images360'
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'images360'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_PORT = 3306执行:
scrapy crawl images
Scrapy对接Selenium
Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态渲染的页面。
在前文中抓取JavaScript渲染的页面有两种方式。
- 一种是分析Ajax请求,找到其对应的接口抓取,Scrapy同样可以用此种方式抓取。
- 一种是直接用Selenium或Splash模拟浏览器进行抓取,
项目地址:https://github.com/Python3WebSpider/ScrapySeleniumTest
新建项目:scrapy startproject scrapyseleniumtest
新建一个Spider:scrapy genspider taobao www.taobao.com
修改ROBOTSTXT OBEY:ROBOTSTXT OBEY = False
- 定义Item
from scrapy import Item, Field
class ProductItem(Item):
collection = 'products'
image = Field()
price = Field()
deal = Field()
title = Field()
shop = Field()
location = Field() - 实现自定义的Spider类
# -*- coding: utf-8 -*-
from scrapy import Request, Spider
from urllib.parse import quote
from scrapyseleniumtest.items import ProductItem
class TaobaoSpider(Spider):
name = 'taobao'
allowed_domains = ['www.taobao.com']
base_url = 'https://s.taobao.com/search?q='
def start_requests(self):
for keyword in self.settings.get('KEYWORDS'):
for page in range(1, self.settings.get('MAX_PAGE') + 1):
url = self.base_url + quote(keyword)
#meta传递分页页码,dongt_filter不去重
yield Request(url=url, callback=self.parse, meta={'page': page}, dont_filter=True)
def parse(self, response):
products = response.xpath(
'//div[@id="mainsrp-itemlist"]//div[@class="items"][1]//div[contains(@class, "item")]')
for product in products:
item = ProductItem()
item['price'] = ''.join(product.xpath('.//div[contains(@class, "price")]//text()').extract()).strip()
item['title'] = ''.join(product.xpath('.//div[contains(@class, "title")]//text()').extract()).strip()
item['shop'] = ''.join(product.xpath('.//div[contains(@class, "shop")]//text()').extract()).strip()
item['image'] = ''.join(product.xpath('.//div[@class="pic"]//img[contains(@class, "img")]/@data-src').extract()).strip()
item['deal'] = product.xpath('.//div[contains(@class, "deal-cnt")]//text()').extract_first()
item['location'] = product.xpath('.//div[contains(@class, "location")]//text()').extract_first()
yield item - 对接Selenium
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from scrapy.http import HtmlResponse
from logging import getLogger
class SeleniumMiddleware():
def __init__(self, timeout=None, service_args=[]):
self.logger = getLogger(__name__)
self.timeout = timeout
self.browser = webdriver.PhantomJS(service_args=service_args)
self.browser.set_window_size(1400, 700)
self.browser.set_page_load_timeout(self.timeout)
self.wait = WebDriverWait(self.browser, self.timeout)
def __del__(self):
self.browser.close()
def process_request(self, request, spider):
"""
用PhantomJS抓取页面
:param request: Request对象
:param spider: Spider对象
:return: HtmlResponse
"""
self.logger.debug('PhantomJS is Starting')
page = request.meta.get('page', 1)
try:
self.browser.get(request.url)
if page > 1:
input = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))
submit = self.wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
self.wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))
return HtmlResponse(url=request.url, body=self.browser.page_source, request=request, encoding='utf-8',
status=200)
except TimeoutException:
return HtmlResponse(url=request.url, status=500, request=request)
def from_crawler(cls, crawler):
return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'),
service_args=crawler.settings.get('PHANTOMJS_SERVICE_ARGS')) - 存储结果
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB'))
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close() - 运行
修改settings.py文件:运行:BOT_NAME = 'scrapyseleniumtest'
SPIDER_MODULES = ['scrapyseleniumtest.spiders']
NEWSPIDER_MODULE = 'scrapyseleniumtest.spiders'
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'scrapyseleniumtest.middlewares.SeleniumMiddleware': 543,
}
ITEM_PIPELINES = {
'scrapyseleniumtest.pipelines.MongoPipeline': 300,
}
KEYWORDS = ['iPad']
MAX_PAGE = 10
SELENIUM_TIMEOUT = 20
PHANTOMJS_SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
MONGO_URI = 'localhost'
MONGO_DB = 'taobao'scrapy crawl taobao
Scrapy对接Splash
注意:使用代理时添加代理的方式应相应更改request.meta['splash'] ['args']['proxy'] = uri
通过实现Downloader Middlewar实现了Selenium的对接,但这种方式是阻塞式的,也就是说这样就破坏了Scrapy异步处理的逻辑,速度会受到影响。为了不破坏其异步加载逻辑,我们可以使用Splash实现。
项目地址:https://github.com/Python3WebSpider/ScrapySplashTest
安装:pip install scrapy-splash
新建项目:scrapy startproject scrapysplashtest
新建一个Spider:scrapy genspider taobao www.taobao.com
添加配置
参考Scrapy-Splash的配置说明进行一步步的配置,链接如下:http://github.com/scrapyplugins/scrapy-splash#configuration
# settings.py |
自定义Spider
# -*- coding: utf-8 -*- |
运行
其他同Selenium对接相同
运行:scrapy crawl taobao
Scrapy通用爬虫
代码地址为:https://github.com/Python3WebSpider/ScrapyUniversal
CrawlSpider
官方文档链接为:http://scrapy.readthedocs.io/en/latest/topics/spiders.html#crawlspider
源码:https://docs.scrapy.org/en/latest/_modules/scrapy/spiders/crawl.html#CrawlSpider
CrawlSpider是Scrapy提供的一个通用Spider。在Spider里,可以指定一些爬取规则来实现页面的提取,这些爬取规则由一个专门的数据结构Rule表示。 Rule里包含提取和跟进页面的配置,Spider会根据Rule来确定当前页面中的哪些链接需要继续爬取、哪些页面的爬取结果需要用哪个方法解析等。
CrawlSpider继承自Spider类。除了Spider类的所有方法和属性,还提供了一个非常重要的属性和方法。
- rules,爬取规则属性,是包含一个或多个Rule对象的列表。每个Rule对爬取网站的动作都做了定义,CrawlSpider会读取rules的每一个Rule并进行解析。
- parse_start_url(),是一个可重写的方法。当start_urls里对应的Request得到Response时,该方法被调用,它会分析Response并必须返回Item 对象或者Request对象。
这里最重要的内容莫过于Rule的定义了,它的定义和参数如下所示:
class scrapy.contrib.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, |
下面依次说明Rule的参数。
link_extractor:Link Extractor对象。通过它,Spider可以知道从爬取的页面中提取哪些链接。提取出的链接会自动生成Request。它又是一个数据结构,一般常用LxmlLinkExtractor对象作为参数,其定义和参数如下所示:
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(),
deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(),
tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True,
process_value=None, strip=True)allow 是一个正则表达式或正则表达式列表,它定义了从当前页面提取出的链接哪些是符合要求的,只有符合要求的链接才会被跟进。
deny 则相反。
allow_domains 定义了符合要求的域名,只有此域名的链接才会被跟进生成新的 Request,它相当于域名白名单。
deny_domains 则相反,相当于域名黑名单。
restrict_xpaths 定义了从当前页面中 XPath 匹配的区域提取链接,其值是 XPath 表达式或 XPath 表达式列表。
restrict_css 定义了从当前页面中 CSS 选择器匹配的区域提取链接,其值是 CSS 选择器或 CSS 选择器列表。
还有一些其他参数代表了提取链接的标签、是否去重、链接的处理等内容,使用的频率不高。可以参考文档的参数说明:
http://scrapy.readthedocs.io/en/latest/topics/link-extractors.html#module-scrapy.linkextractors.lxmlhtml。callback,即回调函数,和之前定义 Request 的 callback 有相同的意义。每次从 link_extractor 中获取到链接时,该函数将会调用。该回调函数接收一个 response 作为其第一个参数,并返回一个包含 Item 或 Request 对象的列表。注意,避免使用 parse () 作为回调函数。由于 CrawlSpider 使用 parse () 方法来实现其逻辑,如果 parse () 方法覆盖了,CrawlSpider 将会运行失败。
cb_kwargs,字典,它包含传递给回调函数的参数。
follow,布尔值,即 True 或 False,它指定根据该规则从 response 提取的链接是否需要跟进。如果 callback 参数为 None,follow 默认设置为 True,否则默认为 False。
process_links,指定处理函数,从 link_extractor 中获取到链接列表时,该函数将会调用,它主要用于过滤。
process_request,同样是指定处理函数,根据该 Rule 提取到每个 Request 时,该函数都会调用,对 Request 进行处理。该函数必须返回 Request 或者 None。
以上内容便是 CrawlSpider 中的核心 Rule 的基本用法。但这些内容可能还不足以完成一个 CrawlSpider 爬虫。下面我们利用 CrawlSpider 实现新闻网站的爬取实例,来更好地理解 Rule 的用法。
Item Loader
我们了解了利用 CrawlSpider 的 Rule 来定义页面的爬取逻辑,这是可配置化的一部分内容。但是,Rule 并没有对 Item 的提取方式做规则定义。对于 Item 的提取,我们需要借助另一个模块 Item Loader 来实现。
Item Loader 提供一种便捷的机制来帮助我们方便地提取 Item。它提供的一系列 API 可以分析原始数据对 Item 进行赋值。Item 提供的是保存抓取数据的容器,而 Item Loader 提供的是填充容器的机制。有了它,数据的提取会变得更加规则化。 Item Loader 的 API 如下所示:
class scrapy.loader.ItemLoader([item, selector, response,] **kwargs) |
Item Loader 的 API 返回一个新的 Item Loader 来填充给定的 Item。如果没有给出 Item,则使用 default_item_class 中的类自动实例化。另外,它传入 selector 和 response 参数来使用选择器或响应参数实例化。 下面将依次说明 Item Loader 的 API 参数。
- item,Item 对象,可以调用 add_xpath ()、add_css () 或 add_value () 等方法来填充 Item 对象。
- selector,Selector 对象,用来提取填充数据的选择器。
- response,Response 对象,用于使用构造选择器的 Response。
一个比较典型的 Item Loader 实例如下:
from scrapy.loader import ItemLoader |
这里首先声明一个 Product Item,用该 Item 和 Response 对象实例化 ItemLoader,调用 add_xpath () 方法把来自两个不同位置的数据提取出来,分配给 name 属性,再用 add_xpath ()、add_css ()、add_value () 等方法对不同属性依次赋值,最后调用 load_item () 方法实现 Item 的解析。
这种方式比较规则化,我们可以把一些参数和规则单独提取出来做成配置文件或存到数据库,即可实现可配置化。
另外,Item Loader 每个字段中都包含了一个 Input Processor(输入处理器)和一个 Output Processor(输出处理器)。Input Processor 收到数据时立刻提取数据,Input Processor 的结果被收集起来并且保存在 ItemLoader 内,但是不分配给 Item。收集到所有的数据后,load_item () 方法被调用来填充再生成 Item 对象。在调用时会先调用 Output Processor 来处理之前收集到的数据,然后再存入 Item 中,这样就生成了 Item。
下面将介绍一些内置的 Processor。
- Identity
Identity 是最简单的 Processor,不进行任何处理,直接返回原来的数据。 - TakeFirst
TakeFirst 返回列表的第一个非空值,类似 extract_first () 的功能,常用作 Output Processor,如下所示:经过此 Processor 处理后的结果返回了第一个不为空的值。from scrapy.loader.processors import TakeFirst
processor = TakeFirst()
print(processor(['', 1, 2, 3]))
Output:
1 - Join
Join 方法相当于字符串的 join () 方法,可以把列表拼合成字符串,字符串默认使用空格分隔,如下所示:from scrapy.loader.processors import Join
processor = Join(',')
print(processor(['one', 'two', 'three']))
Output:
one,two,three - Compose
Compose 是用给定的多个函数的组合而构造的 Processor,每个输入值被传递到第一个函数,其输出再传递到第二个函数,依次类推,直到最后一个函数返回整个处理器的输出,如下所示:在这里我们构造了一个 Compose Processor,传入一个开头带有空格的字符串。Compose Processor 的参数有两个:第一个是 str.upper,它可以将字母全部转为大写;第二个是一个匿名函数,它调用 strip () 方法去除头尾空白字符。Compose 会顺次调用两个参数,最后返回结果的字符串全部转化为大���并且去除了开头的空格。from scrapy.loader.processors import Compose
processor = Compose(str.upper, lambda s: s.strip())
print(processor(' hello world'))
Output:
HELLO WORLD - MapCompose
与 Compose 类似,MapCompose 可以迭代处理一个列表输入值,如下所示:from scrapy.loader.processors import MapCompose
processor = MapCompose(str.upper, lambda s: s.strip())
print(processor(['Hello', 'World', 'Python']))
Output:
['HELLO', 'WORLD', 'PYTHON'] - SelectJmes
SelectJmes 可以查询 JSON,传入 Key,返回查询所得的 Value。不过需要先安装 jmespath 库才可以使用它,命令如下所示:使用这个 Processor ,如下所示:pip3 install jmespath
from scrapy.loader.processors import SelectJmes
proc = SelectJmes('foo')
processor = SelectJmes('foo')
print(processor({'foo': 'bar'}))
Output:
bar
新建项目
首先新建一个 Scrapy 项目,名为 scrapyuniversal,如下所示:
scrapy startproject scrapyuniversal |
创建一个 CrawlSpider,需要先制定一个模板。我们可以先看看有哪些可用模板,命令如下所示:
scrapy genspider -l |
运行结果如下所示:
Available templates: |
之前创建 Spider 的时候,我们默认使用了第一个模板 basic。这次要创建 CrawlSpider,就需要使用第二个模板 crawl,创建命令如下所示:
scrapy genspider -t crawl china tech.china.com |
运行之后便会生成一个 CrawlSpider,其内容如下所示:
from scrapy.linkextractors import LinkExtractor |
这次生成的 Spider 内容多了一个 rules 属性的定义。Rule 的第一个参数是 LinkExtractor,就是上文所说的 LxmlLinkExtractor,只是名称不同。同时,默认的回调函数也不再是 parse,而是 parse_item。
定义 Rule
要实现新闻的爬取,我们需要做的就是定义好 Rule,然后实现解析函数。下面我们就来一步步实现这个过程。 首先将 start_urls 修改为起始链接,代码如下所示:
start_urls = ['http://tech.china.com/articles/'] |
之后,Spider 爬取 start_urls 里面的每一个链接。所以这里第一个爬取的页面就是我们刚才所定义的链接。得到 Response 之后,Spider 就会根据每一个 Rule 来提取这个页面内的超链接,去生成进一步的 Request。接下来,我们就需要定义 Rule 来指定提取哪些链接。构造出一个 Rule ,代码如下所示:
Rule(LinkExtractor(allow='article/.*.html', |
接下来,我们还要让当前页面实现分页功能,所以还需要提取下一页的链接。
下一页节点和其他分页链接区分度不高,要取出此链接我们可以直接用 XPath 的文本匹配方式,所以这里我们直接用 LinkExtractor 的 restrict_xpaths 属性来指定提取的链接即可。另外,我们不需要像新闻详情页一样去提取此分页链接对应的页面详情信息,也就是不需要生成 Item,所以不需要加 callback 参数。另外这下一页的页面如果请求成功了就需要继续像上述情况一样分析,所以它还需要加一个 follow 参数为 True,代表继续跟进匹配分析。其实,follow 参数也可以不加,因为当 callback 为空的时候,follow 默认为 True。此处 Rule 定义为如下所示:
Rule(LinkExtractor(restrict_xpaths='//div[@id="pageStyle"]//a[contains(., "下一页")]')) |
所以现在 rules 就变成了:
rules = (Rule(LinkExtractor(allow='article/.*.html', |
现在已经实现页面的翻页和详情页的抓取了。
解析页面
首先定义一个 Item,如下所示:
from scrapy import Field, Item |
其中站点名称直接赋值为中华网。因为既然是通用爬虫,肯定还有很多爬虫也来爬取同样结构的其他站点的新闻内容,所以需要一个字段来区分一下站点名称。
像之前一样提取内容,就直接调用 response 变量的 xpath ()、css () 等方法即可。这里 parse_item () 方法的实现如下所示:
def parse_item(self, response): |
用 Item Loader,通过 add_xpath ()、add_css ()、add_value () 等方式实现配置化提取。我们可以改写 parse_item (),如下所示:
def parse_item(self, response): |
这里我们定义了一个 ItemLoader 的子类,名为 ChinaLoader,其实现如下所示:
from scrapy.loader import ItemLoader |
ChinaLoader 继承了 NewsLoader 类,其内定义了一个通用的 Out Processor 为 TakeFirst,这相当于之前所定义的 extract_first () 方法的功能。我们在 ChinaLoader 中定义了 text_out 和 source_out 字段。这里使用了一个 Compose Processor,它有两个参数:第一个参数 Join 也是一个 Processor,它可以把列表拼合成一个字符串;第二个参数是一个匿名函数,可以将字符串的头尾空白字符去掉。经过这一系列处理之后,我们就将列表形式的提取结果转化为去除头尾空白字符的字符串。 代码重新运行,提取效果是完全一样的。 至此,我们已经实现了爬虫的半通用化配置。
通用配置抽取
所有的变量都可以抽取,如 name、allowed_domains、start_urls、rules 等。这些变量在 CrawlSpider 初始化的时候赋值即可。我们就可以新建一个通用的 Spider 来实现这个功能,命令如下所示:
scrapy genspider -t crawl universal universal |
接下来,我们将刚才所写的 Spider 内的属性抽离出来配置成一个 JSON,命名为 china.json,放到 configs 文件夹内,和 spiders 文件夹并列,代码如下所示:
{ |
第一个字段 spider 即 Spider 的名称,在这里是 universal。后面是站点的描述,比如站点名称、类型、首页等。随后的 settings 是该 Spider 特有的 settings 配置,如果要覆盖全局项目,settings.py 内的配置可以单独为其配置。随后是 Spider 的一些属性,如 start_urls、allowed_domains、rules 等。rules 也可以单独定义成一个 rules.py 文件,做成配置文件,实现 Rule 的分离,如下所示:
from scrapy.linkextractors import LinkExtractor |
这样我们将基本的配置抽取出来。如果要启动爬虫,只需要从该配置文件中读取然后动态加载到 Spider 中即可。所以我们需要定义一个读取该 JSON 文件的方法,如下所示:
from os.path import realpath, dirname |
定义了 get_config () 方法之后,我们只需要向其传入 JSON 配置文件的名称即可获取此 JSON 配置信息。随后我们定义入口文件 run.py,把它放在项目根目录下,它的作用是启动 Spider,如下所示:
import sys |
运行入口为 run ()。首先获取命令行的参数并赋值为 name,name 就是 JSON 文件的名称,其实就是要爬取的目标网站的名称。我们首先利用 get_config () 方法,传入该名称读取刚才定义的配置文件。获取爬取使用的 spider 的名称、配置文件中的 settings 配置,然后将获取到的 settings 配置和项目全局的 settings 配置做了合并。新建一个 CrawlerProcess,传入爬取使用的配置。调用 crawl () 和 start () 方法即可启动爬取。 在 universal 中,我们新建一个 init() 方法,进行初始化配置,实现如下所示:
from scrapy.linkextractors import LinkExtractor |
在 init() 方法中,start_urls、allowed_domains、rules 等属性被赋值。其中,rules 属性另外读取了 rules.py 的配置,这样就成功实现爬虫的基础配置。 接下来,执行如下命令运行爬虫:
python run.py china |
解析部分同样需要实现可配置化,原来的解析函数如下所示:
def parse_item(self, response): |
我们需要将这些配置也抽离出来。这里的变量主要有 Item Loader 类的选用、Item 类的选用、Item Loader 方法参数的定义,我们可以在 JSON 文件中添加如下 item 的配置:
"item": { |
这里定义了 class 和 loader 属性,它们分别代表 Item 和 Item Loader 所使用的类。定义了 attrs 属性来定义每个字段的提取规则,例如,title 定义的每一项都包含一个 method 属性,它代表使用的提取方法,如 xpath 即代表调用 Item Loader 的 add_xpath () 方法。args 即参数,就是 add_xpath () 的第二个参数,即 XPath 表达式。针对 datetime 字段,我们还用了一次正则提取,所以这里还可以定义一个 re 参数来传递提取时所使用的正则表达式。 我们还要将这些配置之后动态加载到 parse_item () 方法里。最后,最重要的就是实现 parse_item () 方法,如下所示:
def parse_item(self, response): |
再回过头看一下 start_urls 的配置。这里 start_urls 只可以配置具体的链接。如果这些链接有 100 个、1000 个,我们总不能将所有的链接全部列出来吧?在某些情况下,start_urls 也需要动态配置。我们将 start_urls 分成两种,一种是直接配置 URL 列表,一种是调用方法生成,它们分别定义为 static 和 dynamic 类型。 本例中的 start_urls 很明显是 static 类型的,所以 start_urls 配置改写如下所示:
"start_urls": { |
如果 start_urls 是动态生成的,我们可以调用方法传参数,如下所示:
"start_urls": { |
这里 start_urls 定义为 dynamic 类型,指定方法为 urls_china (),然后传入参数 5 和 10,来生成第 5 到 10 页的链接。这样我们只需要实现该方法即可,统一新建一个 urls.py 文件,如下所示:
def china(start, end): |
接下来在 Spider 的 init() 方法中,start_urls 的配置改写如下所示:
from scrapyuniversal import urls |
综上所述,整个项目的配置包括如下内容。
- spider,指定所使用的 Spider 的名称。
- settings,可以专门为 Spider 定制配置信息,会覆盖项目级别的配置。
- start_urls,指定爬虫爬取的起始链接。
- allowed_domains,允许爬取的站点。
- rules,站点的爬取规则。
- item,数据的提取规则。
我们实现了 Scrapy 的通用爬虫,每个站点只需要修改 JSON 文件即可实现自由配置。
Scrapyrt的使用
Scrapyrt 为 Scrapy 提供了一个调度的 HTTP 接口。不需要执行 Scrapy 命令,而是通过请求一个 HTTP 接口即可调度 Scrapy 任务。
安装:pip install scrapyrt
启动服务:scrapyrt [-p 9080]
GET 请求
目前,GET 请求方式支持如下的参数。
- spider_name,Spider 名称,字符串类型,必传参数,如果传递的 Spider 名称不存在则会返回 404 错误。
- url,爬取链接,字符串类型,如果起始链接没有定义的话就必须要传递,如果传递了该参数,Scrapy 会直接用该 URL 生成 Request,而直接忽略 start_requests () 方法和 start_urls 属性的定义。
- callback,回调函数名称,字符串类型,可选参数,如果传递了就会使用此回调函数处理,否则会默认使用 Spider 内定义的回调函数。
- max_requests,最大请求数量,数值类型,可选参数,它定义了 Scrapy 执行请求的 Request 的最大限制,如定义为 5,则最多只执行 5 次 Request 请求,其余的则会被忽略。
- start_requests,是否要执行 start_request () 函数,布尔类型,可选参数,在 Scrapy 项目中如果定义了 start_requests () 方法,那么在项目启动时会默认调用该方法,但是在 Scrapyrt 就不一样了,它默认不执行 start_requests () 方法,如果要执行,需要将它设置为 true。
示例:
curl http://localhost:9080/crawl.json?spider_name=quotes&url=http://quotes.toscrape.com/ |
输出结果返回的是一个 JSON 格式的字符串,解析它的结构,如下所示:
{ |
这里省略了 items 绝大部分。status 显示了爬取的状态,items 部分是 Scrapy 项目的爬取结果,items_dropped 是被忽略的 Item 列表,stats 是爬取结果的统计情况。此结果和直接运行 Scrapy 项目得到的统计是相同的。 这样一来,我们就通过 HTTP 接口调度 Scrapy 项目并获取爬取结果,如果 Scrapy 项目部署在服务器上,我们可以通过开启一个 Scrapyrt 服务实现任务的调度并直接取到爬取结果,这很方便。
POST 请求
此处 Request Body 必须是一个合法的 JSON 配置,在 JSON 里面可以配置相应的参数,支持的配置参数更多。
目前,JSON 配置支持如下参数。
- spider_name:Spider 名称,字符串类型,必传参数。如果传递的 Spider 名称不存在,则返回 404 错误。
- max_requests:最大请求数量,数值类型,可选参数。它定义了 Scrapy 执行请求的 Request 的最大限制,如定义为 5,则表示最多只执行 5 次 Request 请求,其余的则会被忽略。
- request:Request 配置,JSON 对象,必传参数。通过该参数可以定义 Request 的各个参数,必须指定 url 字段来指定爬取链接,其他字段可选。
一个 JSON 配置实例,如下所示:执行如下命令传递该 Json 配置并发起 POST 请求:{
"request": {
"url": "http://quotes.toscrape.com/",
"callback": "parse",
"dont_filter": "True",
"cookies": {"foo": "bar"}
},
"max_requests": 2,
"spider_name": "quotes"
}curl http://localhost:9080/crawl.json -d '{"request": {"url": "http://quotes.toscrape.com/", "dont_filter": "True", "callback": "parse", "cookies": {"foo": "bar"}}, "max_requests": 2, "spider_name": "quotes"}'
Scrapy对接Docker
把前文 Scrapy 的入门项目打包成一个 Docker 镜像。项目爬取的网址为:http://quotes.toscrape.com/,
本章 Scrapy 入门一节已经实现了 Scrapy 对此站点的爬取过程,项目代码为:https://github.com/Python3WebSpider/ScrapyTutorial。
创建 Dockerfile
首先在项目的根目录下新建一个 requirements.txt 文件,将整个项目依赖的 Python 环境包都列出来,可以执行如下命令生成该文件:
# 生成本地全部依赖,适用于虚拟环境 |
或使用pipreqs生成requirements.txt:
pip install pipreqs |
在项目根目录下新建一个 Dockerfile 文件,文件不加任何后缀名,修改内容如下所示:
FROM python:3.7 |
- 第一行的 FROM 代表使用的 Docker 基础镜像,在这里直接使用 python:3.7 的镜像,在此基础上运行 Scrapy 项目。
- 第二行 ENV 是环境变量设置,将 /usr/local/bin:$PATH 赋值给 PATH,即增加 /usr/local/bin 这个环境变量路径。
- 第三行 ADD 是将本地的代码放置到虚拟容器中。它有两个参数:第一个参数是.,代表本地当前路径;第二个参数是 /code,代表虚拟容器中的路径,也就是将本地项目所有内容放置到虚拟容器的 /code 目录下,以便于在虚拟容器中运行代码。
- 第四行 WORKDIR 是指定工作目录,这里将刚才添加的代码路径设成工作路径。这个路径下的目录结构和当前本地目录结构是相同的,所以我们可以直接执行库安装命令、爬虫运行命令等。
- 第五行 RUN 是执行某些命令来做一些环境准备工作。由于 Docker 虚拟容器内只有 Python 3 环境,而没有所需要的 Python 库,所以运行此命令来在虚拟容器中安装相应的 Python 库如 Scrapy,这样就可以在虚拟容器中执行 Scrapy 命令了。
- 第六行 CMD 是容器启动命令。在容器运行时,此命令会被执行。在这里我们直接用 scrapy crawl quotes 来启动爬虫。
修改 MongoDB 连接
如果继续用 localhost 是无法找到 MongoDB 的,因为在 Docker 虚拟容器里 localhost 实际指向容器本身的运行 IP,而容器内部并没有安装 MongoDB,所以爬虫无法连接 MongoDB。 这里的 MongoDB 地址可以有如下两种选择。
- 如果只想在本机测试,我们可以将地址修改为宿主机的 IP,也就是容器外部的本机 IP,一般是一个局域网 IP,使用 ifconfig 命令即可查看。
- 如果要部署到远程主机运行,一般 MongoDB 都是可公网访问的地址,修改为此地址即可。
在本节中,我们的目标是将项目打包成一个镜像,让其他远程主机也可运行这个项目。所以我们直接将此处 MongoDB 地址修改为某个公网可访问的远程数据库地址,修改 MONGO_URI 如下所示:
MONGO_URI = 'mongodb://admin:admin123@120.27.34.25:27017' |
构建镜像
执行如下命令构建镜像:
docker build -t quotes:latest . |
查看一下构建的镜像:
docker images |
运行
在本地测试运行,执行如下命令:
docker run quotes |
推送至 Docker Hub
构建完成之后,我们可以将镜像 Push 到 Docker 镜像托管平台,如 Docker Hub 或者私有的 Docker Registry 等,这样我们就可以从远程服务器下拉镜像并运行了。
以 Docker Hub 为例,如果项目包含一些私有的连接信息(如数据库),我们最好将 Repository 设为私有或者直接放到私有的 Docker Registry。
首先在 https://hub.docker.com 注册一个账号,新建一个 Repository,名为 quotes。比如,我的用户名为 germey,新建的 Repository 名为 quotes,那么此 Repository 的地址就可以用 germey/quotes 来表示。 为新建的镜像打一个标签,命令如下所示:
docker tag quotes:latest germey/quotes:latest |
推送镜像到 Docker Hub 即可,命令如下所示:
docker push germey/quotes |
如果想在其他的主机上运行这个镜像,主机上装好 Docker 后,可以直接执行如下命令:
docker run germey/quotes |
Scrapy爬取新浪微博
60845
scrapy crawl btheavens
scrapy crawl pianku
Ch 13 分布式爬虫
分布式爬虫原理
分布式爬虫架构
Scheduler 可以扩展多个,Downloader 也可以扩展多个。而爬取队列 Queue 必须始终为一个,也就是所谓的共享爬取队列。这样才能保证 Scheduer 从队列里调度某个 Request 之后,其他 Scheduler 不会重复调度此 Request,就可以做到多个 Schduler 同步爬取。这就是分布式爬虫的基本雏形,简单调度架构如图所示。
维护爬取队列
那么这个队列用什么维护来好呢?首先需要考虑的就是性能问题,什么数据库存取效率高?自然想到基于内存存储的 Redis,而且 Redis 还支持多种数据结构,例如列表 List、集合 Set、有序集合 Sorted Set 等等,存取的操作也非常简单,所以在这里采用 Redis 来维护爬取队列。 这几种数据结构存储实际各有千秋,分析如下:
- 列表数据结构有 lpush ()、lpop ()、rpush ()、rpop () 方法,所以我们可以用它来实现一个先进先出式爬取队列,也可以实现一个先进后出栈式爬取队列。
- 集合的元素是无序的且不重复的,这样我们可以非常方便地实现一个随机排序的不重复的爬取队列。
- 有序集合带有分数表示,而 Scrapy 的 Request 也有优先级的控制,所以用有集合我们可以实现一个带优先级调度的队列。
这些不同的队列我们需要根据具体爬虫的需求灵活选择。
去重
Scrapy 有自动去重,它的去重使用了 Python 中的集合。这个集合记录了 Scrapy 中每个 Request 的指纹,这个指纹实际上就是 Request 的散列值。我们可以看看 Scrapy 的源代码,如下所示:
import hashlib |
request_fingerprint () 就是计算 Request 指纹的方法,其方法内部使用的是 hashlib 的 sha1 () 方法。计算的字段包括 Request 的 Method、URL、Body、Headers 这几部分内容,这里只要有一点不同,那么计算的结果就不同。计算得到的结果是加密后的字符串,也就是指纹。每个 Request 都有独有的指纹,指纹就是一个字符串,判定字符串是否重复比判定 Request 对象是否重复容易得多,所以指纹可以作为判定 Request 是否重复的依据。 那么我们如何判定重复呢?Scrapy 是这样实现的,如下所示:
def __init__(self): |
在去重的类 RFPDupeFilter 中,有一个 request_seen () 方法,这个方法有一个参数 request,它的作用就是检测该 Request 对象是否重复。这个方法调用 request_fingerprint () 获取该 Request 的指纹,检测这个指纹是否存在于 fingerprints 变量中,而 fingerprints 是一个集合,集合的元素都是不重复的。如果指纹存在,那么就返回 True,说明该 Request 是重复的,否则这个指纹加入到集合中。如果下次还有相同的 Request 传递过来,指纹也是相同的,那么这时指纹就已经存在于集合中,Request 对象就会直接判定为重复。这样去重的目的就实现了。
Scrapy 的去重过程就是,利用集合元素的不重复特性来实现 Request 的去重。 对于分布式爬虫来说,我们肯定不能再用每个爬虫各自的集合来去重了。因为这样还是每个主机单独维护自己的集合,不能做到共享。多台主机如果生成了相同的 Request,只能各自去重,各个主机之间就无法做到去重了。 那么要实现去重,这个指纹集合也需要是共享的,Redis 正好有集合的存储数据结构,我们可以利用 Redis 的集合作为指纹集合,那么这样去重集合也是利用 Redis 共享的。每台主机新生成 Request 之后,把该 Request 的指纹与集合比对,如果指纹已经存在,说明该 Request 是重复的,否则将 Request 的指纹加入到这个集合中即可。利用同样的原理不同的存储结构我们也实现了分布式 Reqeust 的去重。
防止中断
在 Scrapy 中,爬虫运行时的 Request 队列放在内存中。爬虫运行中断后,这个队列的空间就被释放,此队列就被销毁了。所以一旦爬虫运行中断,爬虫再次运行就相当于全新的爬取过程。
要做到中断后继续爬取,我们可以将队列中的 Request 保存起来,下次爬取直接读取保存数据即可获取上次爬取的队列。我们在 Scrapy 中指定一个爬取队列的存储路径即可,这个路径使用 JOB_DIR 变量来标识,我们可以用如下命令来实现:
scrapy crawl spider -s JOBDIR=crawls/spider |
更加详细的使用方法可以参见官方文档,链接为:https://doc.scrapy.org/en/latest/topics/jobs.html。 在 Scrapy 中,我们实际是把爬取队列保存到本地,第二次爬取直接读取并恢复队列即可。那么在分布式架构中我们还用担心这个问题吗?不需要。因为爬取队列本身就是用数据库保存的,如果爬虫中断了,数据库中的 Request 依然是存在的,下次启动就会接着上次中断的地方继续爬取。 所以,当 Redis 的队列为空时,爬虫会重新爬取;当 Redis 的队列不为空时,爬虫便会接着上次中断之处继续爬取。
Scrapy-Redis源码解析
Scrapy-Redis 库已经为我们提供了 Scrapy 分布式的队列、调度器、去重等功能,其 GitHub 地址为:https://github.com/rmax/scrapy-redis。
获取源码
git clone https://github.com/rmax/scrapy-redis.git |
核心源码在 scrapy-redis/src/scrapy_redis 目录下。
爬取队列
源码文件为 queue.py,它有三个队列的实现,首先它实现了一个父类 Base,提供一些基本方法和属性,如下所示:
class Base(object): |
首先看一下 _encode_request () 和 _decode_request () 方法,因为我们需要把一个 Request 对象存储到数据库中,但数据库无法直接存储对象,所以需要将 Request 序列化转成字符串再存储,而这两个方法就分别是序列化和反序列化的操作。
利用 pickle 库来实现,一般在调用 push () 将 Request 存入数据库时会调用 _encode_request () 方法进行序列化,在调用 pop () 取出 Request 的时候会调用 _decode_request () 进行反序列化。
在父类中 __len()__、push () 和 pop () 方法都是未实现的,会直接抛出 NotImplementedError,因此这个类是不能直接被使用的,所以必须要实现一个子类来重写这三个方法,而不同的子类就会有不同的实现,也就有着不同的功能。 那么接下来就需要定义一些子类来继承 Base 类,并重写这几个方法,那在源码中就有三个子类的实现,它们分别是 FifoQueue、PriorityQueue、LifoQueue,我们分别来看下它们的实现原理。
首先是 FifoQueue:
class FifoQueue(Base): |
这个类继承了 Base 类,并重写了 len()、push ()、pop () 这三个方法,在这三个方法中都是对 server 对象的操作,而 server 对象就是一个 Redis 连接对象,我们可以直接调用其操作 Redis 的方法对数据库进行操作,可以看到这里的操作方法有 llen ()、lpush ()、rpop () 等,代表此爬取队列是使用的 Redis 的列表,序列化后的 Request 会被存入列表中,就是列表的其中一个元素,
len() 方法是获取列表的长度,push () 方法中调用了 lpush () 操作,这代表从列表左侧存入数据,pop () 方法中调用了 rpop () 操作,这代表从列表右侧取出数据。 所以 Request 在列表中的存取顺序是左侧进、右侧出,所以这是有序的进出,即先进先出,英文叫做 First Input First Output,也被简称作 Fifo,而此类的名称就叫做 FifoQueue。
另外还有一个与之相反的实现类,叫做 LifoQueue,实现如下:
class LifoQueue(Base): |
与 FifoQueue 不同的就是它的 pop () 方法,在这里使用的是 lpop () 操作,也就是从左侧出,而 push () 方法依然是使用的 lpush () 操作,是从左侧入。那么这样达到的效果就是先进后出、后进先出,英文叫做 Last In First Out,简称为 Lifo,而此类名称就叫做 LifoQueue。同时这个存取方式类似栈的操作,所以其实也可以称作 StackQueue。
另外在源码中还有一个子类实现,叫做 PriorityQueue,顾名思义,它叫做优先级队列(此队列是默认使用的队列,也就是爬取队列默认是使用有序集合来存储的),实现如下:
class PriorityQueue(Base): |
在这里我们可以看到 len()、push ()、pop () 方法中使用了 server 对象的 zcard ()、zadd ()、zrange () 操作,可以知道这里使用的存储结果是有序集合 Sorted Set,在这个集合中每个元素都可以设置一个分数,那么这个分数就代表优先级。
在 len() 方法里调用了 zcard () 操作,返回的就是有序集合的大小,也就是爬取队列的长度,在 push () 方法中调用了 zadd () 操作,就是向集合中添加元素,这里的分数指定成 Request 的优先级的相反数,因为分数低的会排在集合的前面,所以这里高优先级的Request 就会存在集合的最前面。pop () 方法是首先调用了 zrange () 操作取出了集合的第一个元素,因为最高优先级的 Request 会存在集合最前面,所以第一个元素就是最高优先级的 Request,然后再调用 zremrangebyrank () 操作将这个元素删除,这样就完成了取出并删除的操作。
去重过滤
前面说过 Scrapy 的去重是利用集合来实现的,而在 Scrapy 分布式中的去重就需要利用共享的集合,那么这里使用的就是 Redis 中的集合数据结构。我们来看看去重类是怎样实现的,源码文件是 dupefilter.py,其内实现了一个 RFPDupeFilter 类,如下所示:
class RFPDupeFilter(BaseDupeFilter): |
这里同样实现了一个 request_seen () 方法,和 Scrapy 中的 request_seen () 方法实现极其类似。不过这里集合使用的是 server 对象的 sadd () 操作,也就是集合不再是一个简单数据结构了,而是直接换成了数据库的存储方式。
鉴别重复的方式还是使用指纹,指纹同样是依靠 request_fingerprint () 方法来获取的。获取指纹之后就直接向集合添加指纹,如果添加成功,说明这个指纹原本不存在于集合中,返回值 1。代码中最后的返回结果是判定添加结果是否为 0,如果刚才的返回值为 1,那这个判定结果就是 False,也就是不重复,否则判定为重复。 这样我们就成功利用 Redis 的集合完成了指纹的记录和重复的验证。
调度器
Scrapy-Redis 还帮我们实现了配合 Queue、DupeFilter 使用的调度器 Scheduler,源文件名称是 scheduler.py。我们可以指定一些配置,如 SCHEDULER_FLUSH_ON_START 即是否在爬取开始的时候清空爬取队列,SCHEDULER_PERSIST 即是否在爬取结束后保持爬取队列不清除。我们可以在 settings.py 里自由配置,而此调度器很好地实现了对接。 接下来我们看看两个核心的存取方法,实现如下所示:
def enqueue_request(self, request): |
enqueue_request () 可以向队列中添加 Request,核心操作就是调用 Queue 的 push () 操作,还有一些统计和日志操作。next_request () 就是从队列中取 Request,核心操作就是调用 Queue 的 pop () 操作,此时如果队列中还有 Request,则 Request 会直接取出来,爬取继续,否则如果队列为空,爬取则会重新开始。
总结
- 爬取队列的实现,在这里提供了三种队列,使用了 Redis 的列表或有序集合来维护。
- 去重的实现,使用了 Redis 的集合来保存 Request 的指纹来提供重复过滤。
- 中断后重新爬取的实现,中断后 Redis 的队列没有清空,再次启动时调度器的
next_request ()会从队列中取到下一个 Request,继续爬取。
Scrapy分布式实现
代码地址为:https://github.com/Python3WebSpider/Weibo/tree/distributed
搭建 Redis 服务器
要实现分布式部署,多台主机需要共享爬取队列和去重集合,而这两部分内容都是存于 Redis 数据库中的,我们需要搭建一个可公网访问的 Redis 服务器。
部署代理池和 Cookies 池
将二者放到可以被公网访问的服务器上运行,将代码上传到服务器,修改 Redis 的连接信息配置,用同样的方式运行代理池和 Cookies 池。 远程访问代理池和 Cookies 池提供的接口,来获取随机代理和 Cookies。
PROXY_URL = 'http://120.27.34.25:5555/random' |
配置 Scrapy-Redis
修改 settings.py 配置文件。
- 核心配置
将调度器的类和去重的类替换为 Scrapy-Redis 提供的类,在 settings.py 里面添加如下配置即可:SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" - Redis 连接配置
通过连接字符串配置。分项单独配置。REDIS_URL = 'redis://:foobared@120.27.34.25:6379'
注意,如果配置了 REDIS_URL,那么 Scrapy-Redis 将优先使用 REDIS_URL 连接,会覆盖上面的三项配置。REDIS_HOST = '120.27.34.25'
REDIS_PORT = 6379
REDIS_PASSWORD = 'foobared' - 配置调度队列
此项配置是可选的,默认使用 PriorityQueue。SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' - 配置持久化
此配置是可选的,默认是 False。Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。 如果不想自动清空爬取队列和去重指纹集合,可以增加如下配置:如果强制中断爬虫的运行,爬取队列和去重指纹集合是不会自动清空的。SCHEDULER_PERSIST = True
- 配置重爬
此配置是可选的,默认是 False。如果配置了持久化或者强制中断了爬虫,那么爬取队列和指纹集合不会被清空,爬虫重新启动之后就会接着上次爬取。如果想重新爬取,我们可以配置重爬的选项:SCHEDULER_FLUSH_ON_START = True
- Pipeline 配置
此配置是可选的,默认不启动 Pipeline。Scrapy-Redis 实现了一个存储到 Redis 的 Item Pipeline,启用了这个 Pipeline 的话,爬虫会把生成的 Item 存储到 Redis 数据库中。在数据量比较大的情况下,一般不会这么做。因为 Redis 是基于内存的,我们利用的是它处理速度快的特性,用它来做存储未免太浪费了,配置如下:ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300}
配置存储目标
在服务器上搭建一个 MongoDB 服务,或者直接购买 MongoDB 数据存储服务。 这里使用的就是服务器上搭建的的 MongoDB 服务,IP 仍然为 120.27.34.25,用户名为 admin,密码为 admin123。 修改配置 MONGO_URI 为如下:
MONGO_URI = 'mongodb://admin:admin123@120.27.34.25:27017' |
运行
scrapy crawl weibocn |
Bloom Filter的对接
首先回顾一下 Scrapy-Redis 的去重机制。
Scrapy-Redis 将 Request 的指纹存储到了 Redis 集合中,每个指纹的长度为 40,例如 27adcc2e8979cdee0c9cecbbe8bf8ff51edefb61 就是一个指纹,它的每一位都是 16 进制数。
我们计算一下用这种方式耗费的存储空间。每个十六进制数占用 4 b,1 个指纹用 40 个十六进制数表示,占用空间为 20 B,1 万个指纹即占用空间 200 KB,1 亿个指纹占用 2 GB。
当爬取数量达到上亿级别时,Redis 的占用的内存就会变得很大,而且这仅仅是指纹的存储。Redis 还存储了爬取队列,内存占用会进一步提高,更别说有多个 Scrapy 项目同时爬取的情况了。当爬取达到亿级别规模时,Scrapy-Redis 提供的集合去重已经不能满足我们的要求。所以我们需要使用一个更加节省内存的去重算法 Bloom Filter。
了解 BloomFilter
Bloom Filter,中文名称叫作布隆过滤器,是 1970 年由 Bloom 提出的,它可以被用来检测一个元素是否在一个集合中。Bloom Filter 的空间利用效率很高,使用它可以大大节省存储空间。
Bloom Filter 使用位数组表示一个待检测集合,并可以快速地通过概率算法判断一个元素是否存在于这个集合中。利用这个算法可以实现去重效果。
BloomFilter 的算法
对接 Scrapy-Redis
本节代码地址为:https://github.com/Python3WebSpider/ScrapyRedisBloomFilter。
实现 BloomFilter 时,我们首先要保证不能破坏 Scrapy-Redis 分布式爬取的运行架构,所以我们需要修改 Scrapy-Redis 的源码,将它的去重类替换掉。同时 BloomFilter 的实现需要借助于一个位数组,所以既然当前架构还是依赖于 Redis 的,那么正好位数组的维护直接使用 Redis 就好了。 首先我们实现一个基本的哈希算法,可以实现将一个值经过哈希运算后映射到一个 m 位位数组的某一位上,代码实现如下:
class HashMap(object): |
在这里新建了一个 HashMap 类,构造函数传入两个值,一个是 m 位数组的位数,另一个是种子值 seed,不同的哈希函数需要有不同的 seed,这样可以保证不同的哈希函数的结果不会碰撞。 在 hash () 方法的实现中,value 是要被处理的内容,在这里我们遍历了该字符的每一位并利用 ord () 方法取到了它的 ASCII 码值,然后混淆 seed 进行迭代求和运算,最终会得到一个数值。这个数值的结果就由 value 和 seed 唯一确定,然后我们再将它和 m 进行按位与运算,即可获取到 m 位数组的映射结果,这样我们就实现了一个由字符串和 seed 来确定的哈希函数。当 m 固定时,只要 seed 值相同,就代表是同一个哈希函数,相同的 value 必然会映射到相同的位置。所以如果我们想要构造几个不同的哈希函数,只需要改变其 seed 就好了。
以上便是一个简易的哈希函数的实现。 接下来我们再实现 BloomFilter,BloomFilter 里面需要用到 k 个哈希函数,所以在这里我们需要对这几个哈希函数指定相同的 m 值和不同的 seed 值,在这里构造如下:
BLOOMFILTER_HASH_NUMBER = 6 |
由于我们需要亿级别的数据的去重,即前文介绍的算法中的 n 为 1 亿以上,哈希函数的个数 k 大约取 10 左右的量级,而 m>kn,所以这里 m 值大约保底在 10 亿,由于这个数值比较大,所以这里用移位操作来实现,传入位数 bit,定义 30,然后做一个移位操作 1 <<30,相当于 2 的 30 次方,等于 1073741824,量级也是恰好在 10 亿左右,由于是位数组,所以这个位数组占用的大小就是 2^30b=128MB,而本文开头我们计算过 Scrapy-Redis 集合去重的占用空间大约在 2G 左右,可见 BloomFilter 的空间利用效率之高。 随后我们再传入哈希函数的个数,用它来生成几个不同的 seed,用不同的 seed 来定义不同的哈希函数,这样我们就可以构造一个哈希函数列表,遍历 seed,构造带有不同 seed 值的 HashMap 对象,保存成变量 maps 供后续使用。 另外 server 就是 Redis 连接对象,key 就是这个 m 位数组的名称。
接下来我们就要实现比较关键的两个方法了,一个是判定元素是否重复的方法 exists (),另一个是添加元素到集合中的方法 insert (),实现如下:
def exists(self, value): |
首先我们先看下 insert () 方法,BloomFilter 算法中会逐个调用哈希函数对放入集合中的元素进行运算得到在 m 位位数组中的映射位置,然后将位数组对应的位置置 1,所以这里在代码中我们遍历了初始化好的哈希函数,然后调用其 hash () 方法算出映射位置 offset,再利用 Redis 的 setbit () 方法将该位置 1。 在 exists () 方法中我们就需要实现判定是否重复的逻辑了,方法参数 value 即为待判断的元素,在这里我们首先定义了一个变量 exist,然后遍历了所有哈希函数对 value 进行哈希运算,得到映射位置,然后我们用 getbit () 方法取得该映射位置的结果,依次进行与运算。这样只有每次 getbit () 得到的结果都为 1 时,最后的 exist 才为 True,即代表 value 属于这个集合。如果其中只要有一次 getbit () 得到的结果为 0,即 m 位数组中有对应的 0 位,那么最终的结果 exist 就为 False,即代表 value 不属于这个集合。这样此方法最后的返回结果就是判定重复与否的结果了。 到现在为止 BloomFilter 的实现就已经完成了,我们可以用一个实例来测试一下,代码如下:
conn = StrictRedis(host='localhost', port=6379, password='foobared') |
在这里我们首先定义了一个 Redis 连接对象,然后传递给 BloomFilter,为了避免内存占用过大这里传的位数 bit 比较小,设置为 5,哈希函数的个数设置为 6。 首先我们调用 insert () 方法插入了 Hello 和 World 两个字符串,随后判断了一下 Hello 和 Python 这两个字符串是否存在,最后输出它的结果,运行结果如下:
True |
接下来我们需要继续修改 Scrapy-Redis 的源码,将它的 dupefilter 逻辑替换为 BloomFilter 的逻辑,在这里主要是修改 RFPDupeFilter 类的 request_seen () 方法,实现如下:
def request_seen(self, request): |
首先还是利用 request_fingerprint () 方法获取了 Request 的指纹,然后调用 BloomFilter 的 exists () 方法判定了该指纹是否存在,如果存在,则证明该 Request 是重复的,返回 True,否则调用 BloomFilter 的 insert () 方法将该指纹添加并返回 False,这样就成功利用 BloomFilter 替换了 Scrapy-Redis 的集合去重。 对于 BloomFilter 的初始化定义,我们可以将 init() 方法修改为如下内容:
def __init__(self, server, key, debug, bit, hash_number): |
其中 bit 和 hash_number 需要使用 from_settings () 方法传递,修改如下:
|
其中常量的定义 DUPEFILTER_DEBUG 和 BLOOMFILTER_BIT 统一定义在 defaults.py 中,默认如下:
BLOOMFILTER_HASH_NUMBER = 6 |
到此为止我们就成功实现了 BloomFilter 和 Scrapy-Redis 的对接。
使用
为了方便使用,本节的代码已经打包成了一个 Python 包并发布到了 PyPi,链接为:
https://pypi.python.org/pypi/scrapy-redis-bloomfilter
因此我们以后如果想使用 ScrapyRedisBloomFilter 直接使用就好了,不需要再自己实现一遍。 我们可以直接使用 Pip 来安装,命令如下:
pip install scrapy-redis-bloomfilter |
使用的方法和 Scrapy-Redis 基本相似,在这里说明几个关键配置:
# 去重类,要使用 BloomFilter 请替换 DUPEFILTER_CLASS |
DUPEFILTER_CLASS 是去重类,如果要使用 BloomFilter 需要将 DUPEFILTER_CLASS 修改为该包的去重类。 BLOOMFILTER_HASH_NUMBER 是 BloomFilter 使用的哈希函数的个数,默认为 6,可以根据去重量级自行修改。 BLOOMFILTER_BIT 即前文所介绍的 BloomFilter 类的 bit 参数,它决定了位数组的位数,如果 BLOOMFILTER_BIT 为 30,那么位数组位数为 2 的 30 次方,将占用 Redis 128MB 的存储空间,去重量级在 1 亿左右,即对应爬取量级 1 亿左右。如果爬取量级在 10 亿、20 亿甚至 100 亿,请务必将此参数对应调高。
测试
在源代码中附有一个测试项目,放在 tests 文件夹,该项目使用了 Scrapy-RedisBloomFilter 来去重,Spider 的实现如下:
from scrapy import Request, Spider |
在 start_requests () 方法中首先循环 10 次,构造参数为 0-9 的 URL,然后重新循环了 100 次,构造了参数为 0-99 的 URL,那么这里就会包含 10 个重复的 Request,我们运行项目测试一下:
scrapy crawl test |
可以看到最后统计的第一行的结果:
'bloomfilter/filtered': 10, |
这就是 BloomFilter 过滤后的统计结果,可以看到它的过滤个数为 10 个,也就是它成功将重复的 10 个 Reqeust 识别出来了,测试通过。
Ch 14 分布式爬虫的部署
Scrapyd分布式部署
了解 Scrapyd
Scrapyd 是一个运行 Scrapy 爬虫的服务程序,它提供一系列 HTTP 接口来帮助我们部署、启动、停止、删除爬虫程序。Scrapyd 支持版本管理,同时还可以管理多个爬虫任务,利用它我们可以非常方便地完成 Scrapy 爬虫项目的部署任务调度。
安装
pip install scrapyd |
Scrapyd 的功能
- daemonstatus.json
这个接口负责查看 Scrapyd 当前的服务和任务状态,我们可以用 curl 命令来请求这个接口,命令如下:结果:curl http://139.217.26.30:6800/daemonstatus.json
返回结果是 Json 字符串,status 是当前运行状态, finished 代表当前已经完成的 Scrapy 任务,running 代表正在运行的 Scrapy 任务,pending 代表等待被调度的 Scrapyd 任务,node_name 就是主机的名称。{"status": "ok", "finished": 90, "running": 9, "node_name": "datacrawl-vm", "pending": 0}
- addversion.json
这个接口主要是用来部署 Scrapy 项目用的,在部署的时候我们需要首先将项目打包成 Egg 文件,然后传入项目名称和部署版本。 我们可以用如下的方式实现项目部署:在这里 -F 即代表添加一个参数,同时我们还需要将项目打包成 Egg 文件放到本地。curl http://120.27.34.25:6800/addversion.json -F project=wenbo -F version=first -F egg=@weibo.egg
- schedule.json
这个接口负责调度已部署好的 Scrapy 项目运行。 我们可以用如下接口实现任务调度:在这里需要传入两个参数,project 即 Scrapy 项目名称,spider 即 Spider 名称。 返回结果如下:curl http://120.27.34.25:6800/schedule.json -d project=weibo -d spider=weibocn
status 代表 Scrapy 项目启动情况,jobid 代表当前正在运行的爬取任务代号。{"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
- cancel.json
这个接口可以用来取消某个爬取任务,如果这个任务是 pending 状态,那么它将会被移除,如果这个任务是 running 状态,那么它将会被终止。 我们可以用下面的命令来取消任务的运行:在这里需要传入两个参数,project 即项目名称,job 即爬取任务代号。返回结果如下:curl http://120.27.34.25:6800/cancel.json -d project=weibo -d job=6487ec79947edab326d6db28a2d86511e8247444
status 代表请求执行情况,prevstate 代表之前的运行状态。{"status": "ok", "prevstate": "running"}
- listprojects.json
这个接口用来列出部署到 Scrapyd 服务上的所有项目描述。 我们可以用下面的命令来获取 Scrapyd 服务器上的所有项目描述:curl http://120.27.34.25:6800/listprojects.json
- listversions.json
这个接口用来获取某个项目的所有版本号,版本号是按序排列的,最后一个条目是最新的版本号。 我们可以用如下命令来获取项目的版本号:curl http://120.27.34.25:6800/listversions.json?project=weibo
- listspiders.json
这个接口用来获取某个项目最新的一个版本的所有 Spider 名称。 我们可以用如下命令来获取项目的 Spider 名称:curl http://120.27.34.25:6800/listspiders.json?project=weibo
- listjobs.json
这个接口用来获取某个项目当前运行的所有任务详情。 我们可以用如下命令来获取所有任务详情:在这里需要一个参数 project,就是项目的名称。 返回结果如下:curl http://120.27.34.25:6800/listjobs.json?project=weibo
status 代表请求执行情况,pendings 代表当前正在等待的任务,running 代表当前正在运行的任务,finished 代表已经完成的任务。{"status": "ok",
"pending": [{"id": "78391cc0fcaf11e1b0090800272a6d06", "spider": "weibocn"}],
"running": [{"id": "422e608f9f28cef127b3d5ef93fe9399", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664"}],
"finished": [{"id": "2f16646cfcaf11e1b0090800272a6d06", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664", "end_time": "2017-07-12 10:24:03.594664"}]} - delversion.json
这个接口用来删除项目的某个版本。 我们可以用如下命令来删除项目版本:curl http://120.27.34.25:6800/delversion.json -d project=weibo -d version=v1
- delproject.json
这个接口用来删除某个项目。 我们可以用如下命令来删除某个项目:curl http://120.27.34.25:6800/delproject.json -d project=weibo
ScrapydAPI 的使用
安装:pip install python-scrapyd-api
ScrapydAPI 库对这些接口又做了一层封装。下面我们来看下 ScrapydAPI 的使用方法,其实核心原理和 HTTP 接口请求方式并无二致,只不过用 Python 封装后使用更加便捷。 我们可以用如下方式建立一个 ScrapydAPI 对象:
from scrapyd_api import ScrapydAPI |
然后就可以调用它的方法来实现对应接口的操作了,例如部署的操作可以使用如下方式:
egg = open('weibo.egg', 'rb') |
这样我们就可以将项目打包为 Egg 文件,然后把本地打包的的 Egg 项目部署到远程 Scrapyd 了。 另外 ScrapydAPI 还实现了所有 Scrapyd 提供的 API 接口,名称都是相同的,参数也是相同的。 例如我们可以调用 list_projects () 方法即可列出 Scrapyd 中所有已部署的项目:
scrapyd.list_projects() |
更加详细的操作可以参考其官方文档:http://python-scrapyd-api.readthedocs.io/
Scrapy-Client使用
Scrapyd-Client用来完成部署过程。
安装
pip install scrapyd-client |
Scrapyd-Client 的功能
Scrapyd-Client 为了方便 Scrapy 项目的部署,提供两个功能:
- 将项目打包成 Egg 文件。
- 将打包生成的 Egg 文件通过 addversion.json 接口部署到 Scrapyd 上。
也就是说,Scrapyd-Client 帮我们把部署全部实现了,我们不需要再去关心 Egg 文件是怎样生成的,也不需要再去读 Egg 文件并请求接口上传了,这一切的操作只需要执行一个命令即可一键部署。
Scrapyd-Client 部署
要部署 Scrapy 项目,我们首先需要修改一下项目的配置文件,例如我们之前写的 Scrapy 微博爬虫项目,在项目的第一层会有一个 scrapy.cfg 文件,在这里我们需要配置一下 deploy 部分,例如我们要将项目部署到 120.27.34.25 的 Scrapyd 上,修改内容如下:
[settings] |
这样我们再在 scrapy.cfg 文件所在路径执行如下命令:
scrapyd-deploy |
我们也可以指定项目版本,如果不指定的话默认为当前时间戳,指定的话通过 version 参数传递即可,例如:
scrapyd-deploy --version 201707131455 |
值得注意的是在 Python3 的 Scrapyd 1.2.0 版本中我们不要指定版本号为带字母的字符串,需要为纯数字,否则可能会出现报错。 另外如果我们有多台主机,我们可以配置各台主机的别名,例如可以修改配置文件为:
[deploy:vm1] |
如果我们想将项目部署到 IP 为 139.217.26.30 的 vm2 主机,我们只需要执行如下命令:
scrapyd-deploy vm2 |
这样我们就可以将项目部署到名称为 vm2 的主机上了。 如此一来,如果我们有多台主机,我们只需要在 scrapy.cfg 文件中配置好各台主机的 Scrapyd 地址,然后调用 scrapyd-deploy 命令加主机名称即可实现部署,非常方便。
如果 Scrapyd 设置了访问限制的话,我们可以在配置文件中加入用户名和密码的配置,同时端口修改一下,修改成 Nginx 代理端口,如在第一章我们使用的是 6801,那么这里就需要改成 6801,修改如下:
[deploy:vm1] |
Scrapyd对接Docker
需要解决一个痛点,那就是 Python 环境配置问题和版本冲突解决问题。如果我们将 Scrapyd 直接打包成一个 Docker 镜像,那么在服务器上只需要执行 Docker 命令就可以启动 Scrapyd 服务,这样就不用再关心 Python 环境问题,也不需要担心版本冲突问题。 接下来,我们就将 Scrapyd 打包制作成一个 Docker 镜像。
对接 Docker
首先新建一个项目,然后新建一个 scrapyd.conf,即 Scrapyd 的配置文件,内容如下:
[scrapyd] |
在这里实际上是修改自官方文档的配置文件:
https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file,
其中修改的地方有两个:
- max_proc_per_cpu = 10,原本是 4,即 CPU 单核最多运行 4 个 Scrapy 任务,也就是说 1 核的主机最多同时只能运行 4 个 Scrapy 任务,在这里设置上限为 10,也可以自行设置。
- bind_address = 0.0.0.0,原本是 127.0.0.1,不能公开访问,在这里修改为 0.0.0.0 即可解除此限制。
接下来新建一个 requirements.txt ,将一些 Scrapy 项目常用的库都列进去,内容如下:
requests |
如果我们运行的 Scrapy 项目还有其他的库需要用到可以自行添加到此文件中。 最后我们新建一个 Dockerfile,内容如下:
FROM python:3.7 |
- 第一行 FROM 是指在 python:3.6 这个镜像上构建,也就是说在构建时就已经有了 Python 3.6 的环境。
- 第二行 ADD 是将本地的代码放置到虚拟容器中,它有两个参数,第一个参数是 . ,即代表本地当前路径,/code 代表虚拟容器中的路径,也就是将本地项目所有内容放置到虚拟容器的 /code 目录下。
- 第三行 WORKDIR 是指定工作目录,在这里将刚才我们添加的代码路径设成工作路径,在这个路径下的目录结构和我们当前本地目录结构是相同的,所以可以直接执行库安装命令等。
- 第四行 COPY 是将当前目录下的 scrapyd.conf 文件拷贝到虚拟容器的 /etc/scrapyd/ 目录下,Scrapyd 在运行的时候会默认读取这个配置。
- 第五行 EXPOSE 是声明运行时容器提供服务端口,注意这里只是一个声明,在运行时不一定就会在此端口开启服务。这样的声明一是告诉使用者这个镜像服务的运行端口,以方便配置映射。另一个用处则是在运行时使用随机端口映射时,会自动随机映射 EXPOSE 的端口。
- 第六行 RUN 是执行某些命令,一般做一些环境准备工作,由于 Docker 虚拟容器内只有 Python3 环境,而没有我们所需要的一些 Python 库,所以在这里我们运行此命令来在虚拟容器中安装相应的 Python 库,这样项目部署到 Scrapyd 中便可以正常运行了。
- 第七行 CMD 是容器启动命令,在容器运行时,会直接执行此命令,在这里我们直接用 scrapyd 来启动 Scrapyd 服务。
到现在基本的工作就完成了,运行如下命令进行构建:
docker build -t scrapyd:latest . |
构建成功后即可运行测试:
docker run -d -p 6800:6800 scrapyd |
将此镜像上传到 Docker Hub,例如我的 Docker Hub 用户名为 germey,新建了一个名为 scrapyd 的项目,首先可以打一个标签:
docker tag scrapyd:latest germey/scrapyd:latest |
这里请自行替换成你的项目名称。 然后 Push 即可:
docker push germey/scrapyd:latest |
之后我们在其他主机运行此命令即可启动 Scrapyd 服务:
docker run -d -p 6800:6800 germey/scrapyd |
Scrapyd批量部署
我们在上一节实现了 Scrapyd 和 Docker 的对接,这样每台主机就不用再安装 Python 环境和安装 Scrapyd 了,直接执行一句 Docker 命令运行 Scrapyd 服务即可。但是这种做法有个前提,那就是每台主机都安装 Docker,然后再去运行 Scrapyd 服务。如果我们需要部署 10 台主机的话,工作量确实不小。
一种方案是,一台主机已经安装好各种开发环境,我们取到它的镜像,然后用镜像来批量复制多台主机,批量部署就可以轻松实现了。
另一种方案是,我们在新建主机的时候直接指定一个运行脚本,脚本里写好配置各种环境的命令,指定其在新建主机的时候自动执行,那么主机创建之后所有的环境就按照自定义的命令配置好了,这样也可以很方便地实现批量部署。
目前很多服务商都提供云主机服务,如阿里云、腾讯云、Azure、Amazon 等,不同的服务商提供了不同的批量部署云主机的方式。例如,腾讯云提供了创建自定义镜像的服务,在新建主机的时候使用自定义镜像创建新的主机即可,这样就可以批量生成多个相同的环境。Azure 提供了模板部署的服务,我们可以在模板中指定新建主机时执行的配置环境的命令,这样在主机创建之后环境就配置完成了。 本节我们就来看看这两种批量部署的方式,来实现 Docker 和 Scrapyd 服务的批量部署。
镜像部署
模板部署
Gerapy分布式管理
我们可以通过 Scrapyd-Client 将 Scrapy 项目部署到 Scrapyd 上,并且可以通过 Scrapyd API 来控制 Scrapy 的运行。那么,我们是否可以做到更优化?方法是否可以更方便可控? 我们重新分析一下当前可以优化的问题。
使用 Scrapyd-Client 部署时,需要在配置文件中配置好各台主机的地址,然后利用命令行执行部署过程。如果我们省去各台主机的地址配置,将命令行对接图形界面,只需要点击按钮即可实现批量部署,这样就更方便了。
使用 Scrapyd API 可以控制 Scrapy 任务的启动、终止等工作,但很多操作还是需要代码来实现,同时获取爬取日志还比较烦琐。如果我们有一个图形界面,只需要点击按钮即可启动和终止爬虫任务,同时还可以实时查看爬取日志报告,那这将大大节省我们的时间和精力。
所以我们的终极目标是如下内容。
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
而这所有的工作均可通过 Gerapy 来实现。 Gerapy 是一个基于 Scrapyd、Scrapyd API、Django、Vue.js 搭建的分布式爬虫管理框架。接下来将简单介绍它的使用方法。
Gerapy 的 GitHub 地址:https://github.com/Gerapy。
安装
pip install gerapy |
使用说明
首先可以利用 gerapy 命令新建一个项目,命令如下:
gerapy init |
这样会在当前目录下生成一个 gerapy 文件夹,然后进入 gerapy 文件夹,会发现一个空的 projects 文件夹,我们后文会提及。 这时先对数据库进行初始化:
gerapy migrate |
这样即会生成一个 SQLite 数据库,数据库中会用于保存各个主机配置信息、部署版本等。 接下来启动 Gerapy 服务,命令如下:
gerapy runserver |
这样即可在默认 8000 端口上开启 Gerapy 服务,我们浏览器打开:http://localhost:8000 即可进入 Gerapy 的管理页面,在这里提供了主机管理和项目管理的功能。 主机管理中,我们可以将各台主机的 Scrapyd 运行地址和端口添加,并加以名称标记,添加之后便会出现在主机列表中,Gerapy 会监控各台主机的运行状况并以不同的状态标识
Splash中的CrawlSpider模块源码解析
地址:https://docs.scrapy.org/en/latest/_modules/scrapy/spiders/crawl.html#CrawlSpider
""" |
Rule类
class scrapy.spiders.Rule(link_extractor=None, callback=None, cb_kwargs=None, |
class Rule: |